Vision + Language: How Multimodal LLMs Actually Work (And When to Use Them)
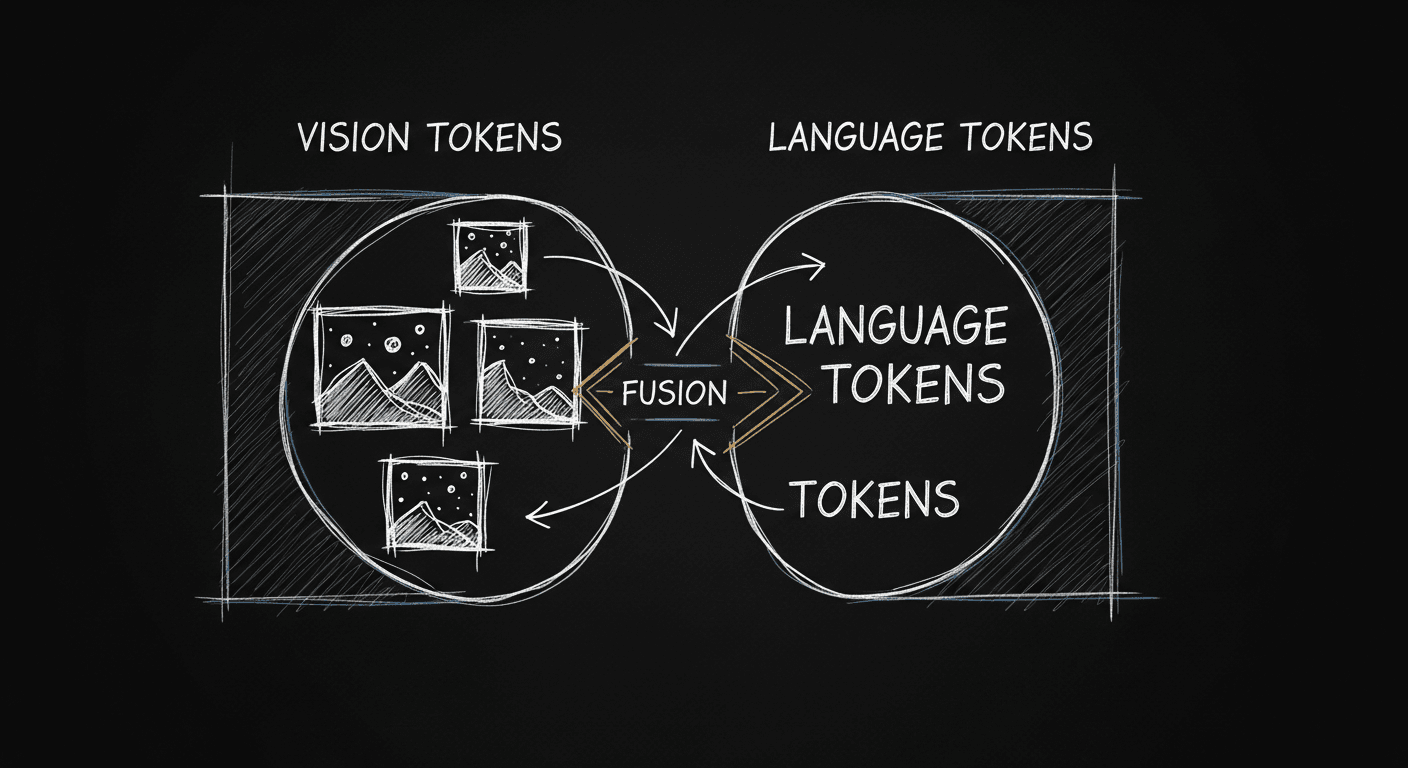
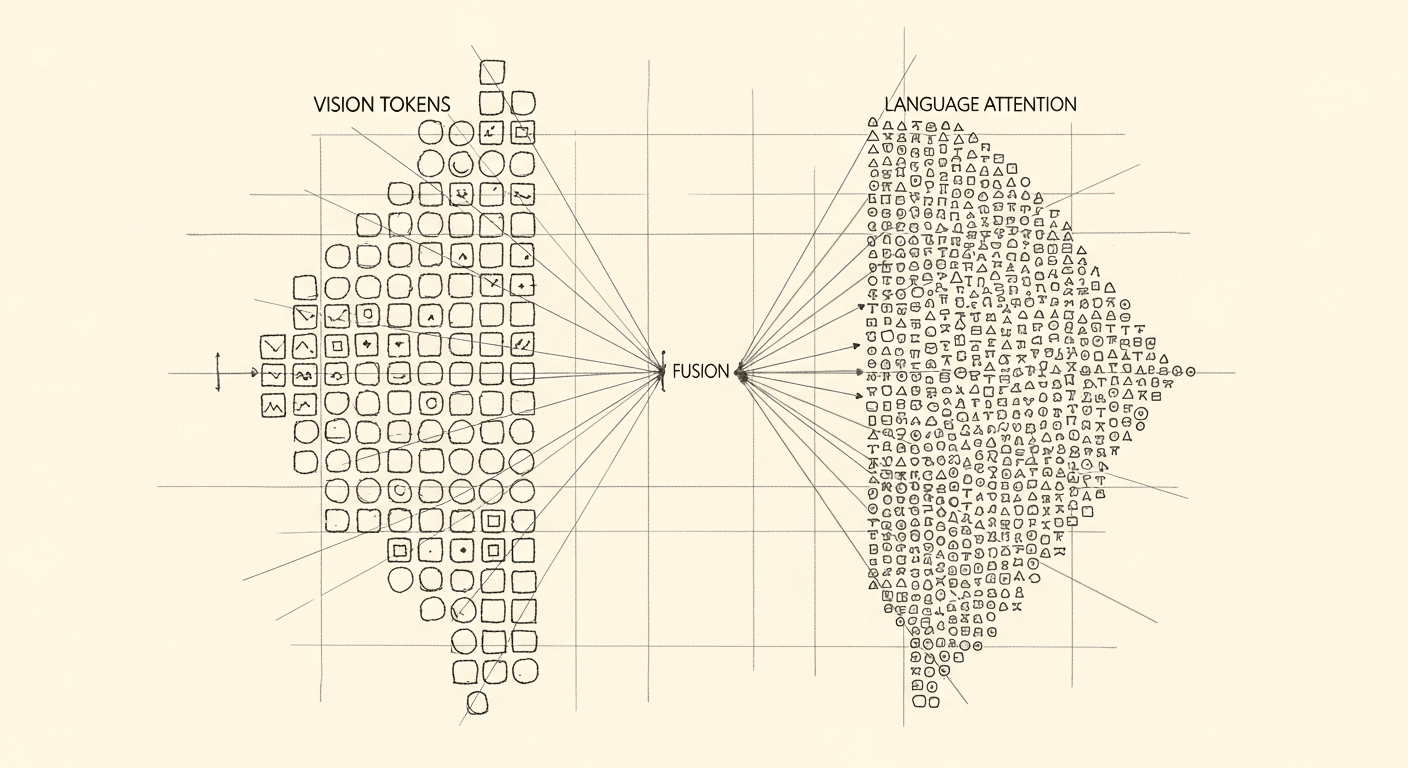
What actually happens when a model reads an image
Two years ago, I was working on a prior authorization workflow at a health system. The bottleneck was radiology reports: specifically, the gap between what a radiologist wrote and what a payer's criteria actually required for approval. We had solid text-based extraction working on the report narrative. What we couldn't touch was the imaging itself.
The clinical team kept flagging cases where the written report said "mild effusion" but the image clearly showed something the radiologist had understated, or where the wording didn't capture what the payer needed. Text-only AI had a ceiling. The ceiling was the image.
That's when the question became real for me: what does it take to give a language model vision? Not as a philosophy exercise, but as an engineering problem with real constraints and production requirements.
Here is what I've learned since.
What Multimodal Actually Means
"Multimodal" gets used loosely enough that it's nearly lost meaning. For practical purposes, a multimodal LLM is a language model that accepts image inputs and reasons about them in the same context as text. The model produces text output. It doesn't generate images; it understands them.
The input side is where the architecture diverges. You have an image. The model needs to process it. There are two fundamentally different ways to wire this together, and they have meaningfully different properties.
Before you can reason about images, you need to represent them. Visual encoders, typically vision transformers (ViTs), convert an image into a sequence of patch embeddings. A ViT divides an image into fixed-size patches (16×16 pixels is common), linearly projects each patch into a vector, and produces a sequence of visual tokens, often 196–1024 per image depending on resolution and patch size. Those visual tokens are then handed off to whatever integration architecture the model uses.
The choice of architecture determines how much the language model can "see" those tokens, how much VRAM they consume, and how fine-grained the visual reasoning can be.
Architecture One: Decoder-Only (Embedding Injection)
The simpler approach: treat visual tokens exactly like text tokens.
After the vision encoder produces patch embeddings, a projection layer (usually a small MLP or linear transformation) maps them into the language model's embedding space. These projected image embeddings are concatenated with the text token embeddings and fed into the decoder as a single flat sequence.
From the language model's perspective, an image is just a long sequence of tokens that happen to represent visual content. The self-attention mechanism in the decoder handles the rest. It can attend to any image token from any text token and vice versa.
Llama 3.2 Vision is built this way. Meta's choice to go decoder-only is a strong endorsement of the approach's practicality: it's the simplest possible integration, it works with the same training infrastructure you already have for text-only models, and in 2025 it proved capable enough to handle real vision-language tasks in production.
The practical tradeoff: simplicity comes at a token budget cost. A 336×336 image at 14×14 patch size produces 576 image tokens. A higher-resolution image, say 1024×1024, produces 4,096 image tokens. At an 8K context window, a handful of high-res images can consume most of your available context before a single word of text. For radiology images, which routinely need high resolution to capture clinically relevant detail, this is not a theoretical concern. It's a hard constraint you will hit in production.
Continuous embedding injection, where visual features are projected as a continuous vector rather than discretized into a codebook, is now the dominant approach within this family. It's simpler than tokenizing images into discrete codes, and empirically outperforms discrete approaches on most vision-language benchmarks.
Architecture Two: Cross-Attention
The second approach keeps the visual and language processing streams separate longer, connecting them through dedicated cross-attention layers inserted into the language model.
Here, the decoder's attention layers are modified: in addition to the standard self-attention over text tokens, each modified layer includes a cross-attention step where text tokens can attend to the full set of image features from the vision encoder. The vision encoder's output is never concatenated into the text sequence. It lives in a separate buffer that the cross-attention mechanism reads.
Flamingo, from DeepMind, was the most influential early model in this family. The key architectural advantage is control: you can precisely regulate how much influence visual information has at each layer. You can freeze the language backbone entirely and only train the cross-attention connectors and the vision encoder, which is useful when you want to preserve the language model's existing capabilities while adding vision.
The cost is complexity. Your training code, serving infrastructure, and memory management all need to handle two parallel processing streams. Cross-attention layers add parameters. The overall system is harder to reason about when something goes wrong.
When cross-attention earns its complexity: fine-grained visual reasoning tasks. Detailed image description, dense object detection, pathology slide analysis where spatial relationships matter at the patch level. If your use case requires the model to track fine spatial structure across an entire high-resolution image and integrate that structure with language in a nuanced way, cross-attention gives you more levers to work with.
The Token Budget Problem (And Why It Dominates Every Other Decision)
Textbook architecture diagrams don't prepare you for this part.
Language models have finite context windows. Image tokens consume that context in large chunks. If you're building a production system that needs to process images, you have to decide: what resolution do your images actually need to be, and how many can you fit per request?
A few concrete numbers for a decoder-only model with 8K context:
| Image resolution | Patch size | Tokens used | Text tokens remaining |
|---|---|---|---|
| 224×224 | 14×14 | 256 | ~7,700 |
| 336×336 | 14×14 | 576 | ~7,400 |
| 672×672 | 14×14 | 2,304 | ~5,700 |
| 1024×1024 | 14×14 | 5,329 | ~2,600 |
Radiology images are typically 512×512 to 4096×4096 pixels. Full-resolution CT slices at 512×512 are borderline workable in an 8K context. Anything bigger requires either downsampling, which may destroy clinically relevant detail, or a model with a much larger context window.
This is why clinical imaging use cases push toward cross-attention architectures or toward specialized medical vision encoders that compress image features more aggressively before the language model ever sees them. The token budget isn't an implementation detail. It shapes the clinical capability ceiling.
Healthcare AI: Where Multimodal Gets Serious
Four clinical imaging modalities are where vision plus language genuinely changes what's possible: radiology (X-ray, CT, MRI), pathology slides, clinical photography (wound assessment, dermatology), and ophthalmology imaging (retinal scans, OCR of handwritten forms). Each has different resolution requirements, different annotation challenges, and different regulatory considerations.
Radiology is the most developed. GPT-4V, Llama 3.2 Vision, and purpose-built models like MedPaLM-M have all shown meaningful performance on chest X-ray interpretation tasks. The architecture decision for a production radiology application usually lands on decoder-only with careful image preprocessing: downsampling to 336–512px with a clinical radiologist's input on what detail level is acceptable to lose.
Pathology slides are harder. A single whole-slide image is gigapixel-scale. You can't fit that into any current model context. The standard approach is patch-based: tile the slide into manageable patches, run inference on patches, aggregate. This is less a model architecture problem and more a pipeline architecture problem. The model only ever sees a patch, and you need a second-stage aggregator to synthesize patch-level predictions into a slide-level assessment.
Clinical photography is where decoder-only shines cleanly. Wound photos, dermatology images, and patient-facing clinical photos are typically 1–4 megapixels but clinically relevant at 336–512px resolution. Token budgets are manageable, resolution requirements are met, and you can run multiple images per context.
The HIPAA overlay is non-negotiable across all of these. Images are PHI. Any pipeline that sends clinical images to a third-party API, including a multimodal API endpoint, needs a BAA in place and needs to be scoped carefully for minimum necessary data. For most health system builds, this means self-hosting the model or using a cloud provider's HIPAA-eligible AI services rather than consumer API endpoints.
When Multimodal Improves Over Text-Only
Not every use case that could be multimodal should be. Before committing to a vision plus language architecture, ask honestly: does the image contain information that the accompanying text does not?
For clinical documentation, the answer is often no. A radiology report that says "right lower lobe consolidation, 3.2 cm, no pleural effusion" already contains the information the image contains, in text form, extracted by the radiologist. Running that report through a multimodal model alongside the image adds complexity without adding information.
Where multimodal genuinely adds value:
- Images without adequate text descriptions: clinical photos with sparse notes, unlabeled slides, scanned handwritten records where OCR is insufficient
- Discrepancy detection: comparing a written report's claims against the image to flag potential errors or omissions
- Structured extraction from visual sources: pulling data from scanned forms, tables in images, or diagram-heavy clinical documents that are impractical to process through standard text extraction
- Patient-facing applications: tools where patients upload their own images (wound photos, medication labels, discharge papers) and need interpretation
The honest default: if you have good text, use text. Multimodal isn't a quality multiplier on top of good text data. It's a capability unlock for information that only exists in visual form.
Making the Architecture Decision
The practical decision tree is shorter than the theory suggests.
Start with decoder-only. It works, it's simpler, and Llama 3.2 Vision's production viability has removed the "this is research-grade only" objection. The continuous embedding injection approach is mature. You can run it on the same serving infrastructure as your text models with modest modifications.
Move to cross-attention when you need fine-grained visual control that decoder-only can't deliver. In clinical practice, that usually means dense pathology slide analysis or cases where you need to tune the vision-language interaction precisely without disturbing the language model's existing behavior. If you're fine-tuning on clinical images and need to preserve the language backbone's existing medical knowledge while adapting only the visual integration, cross-attention's modular training approach is a genuine advantage.
In either case, settle your image preprocessing pipeline before you settle your model choice. Understand what resolution your clinical task requires versus what you can afford in tokens. If those numbers don't reconcile, no architecture choice will save you. You need a different approach to image encoding or a larger context window.
What I'd Build Today
If I were back at that prior authorization workflow with current tooling, I'd start with Llama 3.2 Vision 11B: decoder-only, runs on a single A10G, 128K context window gives a reasonable image budget. I'd pair it with a preprocessing pipeline that downsamples radiology images to 336px before injection. Self-hosted behind a HIPAA-compliant boundary.
I'd validate two things explicitly before calling it production-ready: whether the downsampled resolution preserves the clinical signal I need (this requires radiologist evaluation, not benchmark scores), and whether the model does better than text-only on real cases where the image contains information the report text doesn't capture. If both answers are yes, I have a genuine multimodal use case. If only one is yes, I probably have a text problem disguised as a multimodal problem.
The technology is real and practical today in a way it wasn't even eighteen months ago. The hard part isn't the architecture. It's being honest about whether vision adds something your specific use case doesn't already get from text.
That question is worth answering rigorously before you build anything.