From GPT-2 to DeepSeek: The Architectural Changes That Actually Mattered
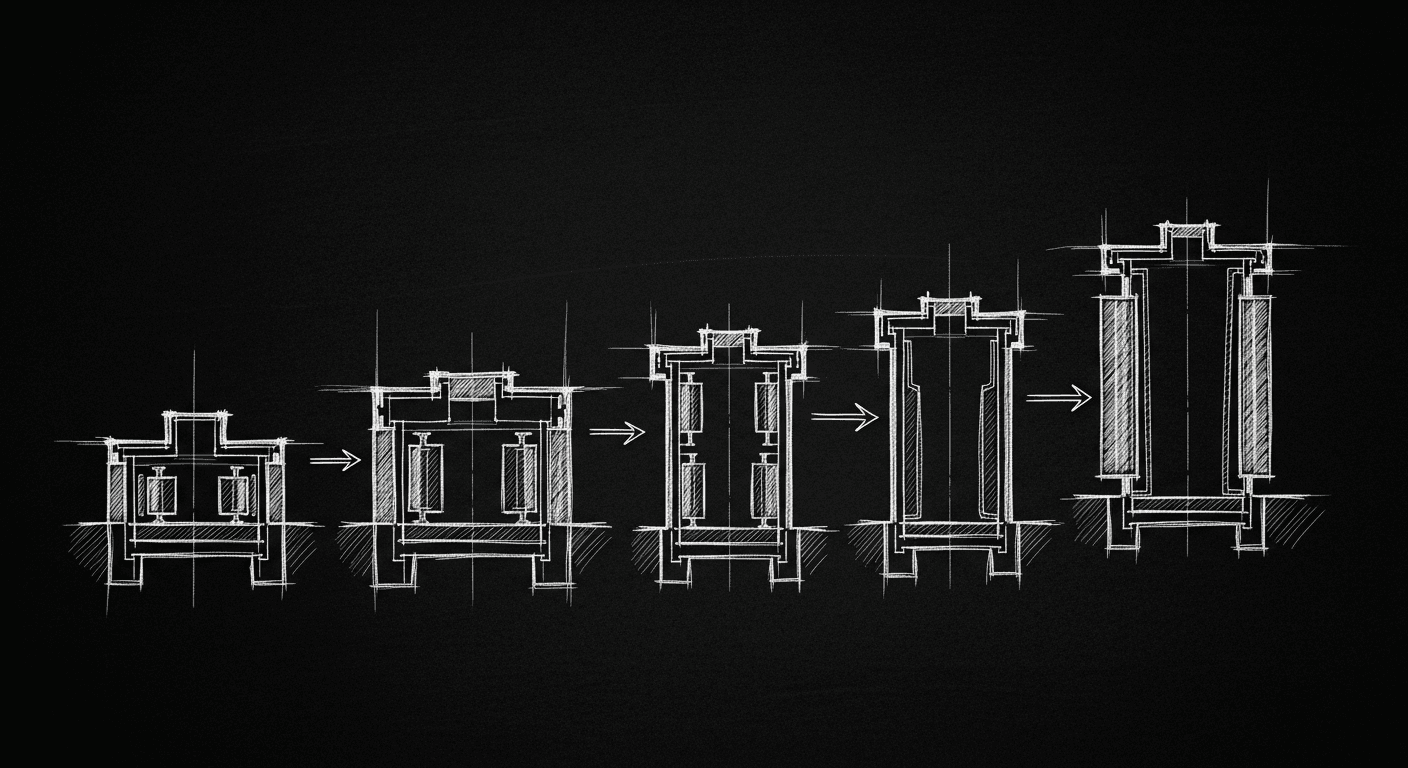
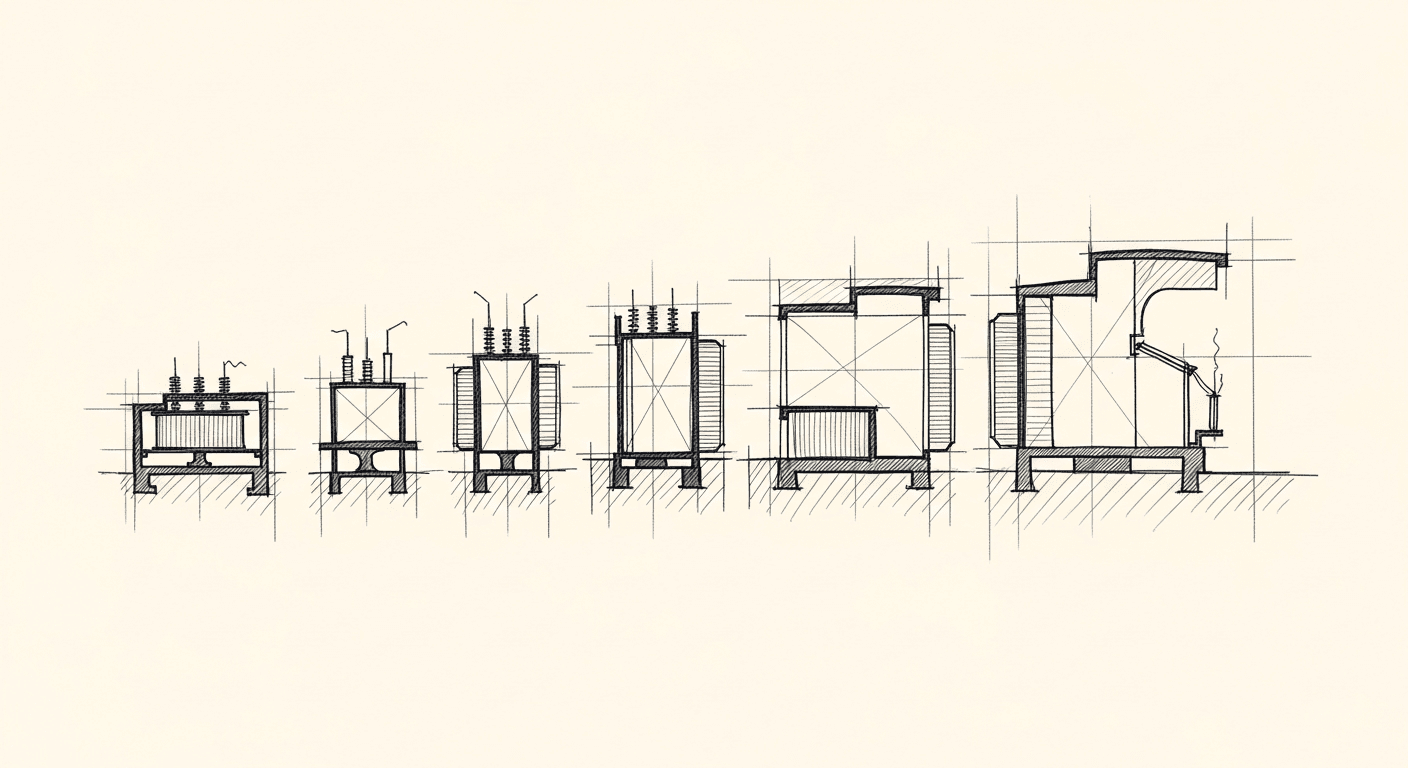
Not all papers matter. These ones changed the structure of the field.
I've been reading ML papers for 10 years. Most don't matter. These architectural choices did.
Not because they were elegant on paper. Because they solved real problems that were quietly killing scale. When you train a system on tens of billions of tokens and the architecture has a flaw — maybe it can't handle long sequences, or the KV cache is blowing out GPU memory — you notice. The field noticed. Each of the changes I'm going to describe here was a direct answer to something that wasn't working.
After comparing the major LLM architectures from GPT-2 through DeepSeek V3, what strikes me isn't the breadth. It's the clarity of the pattern. A handful of architectural choices account for most of the practical capability gains in the last six years. The rest is implementation detail.
Here's my read on what mattered and why.
What GPT-2 Got Right
Before talking about what changed, it's worth being precise about what GPT-2 established that has basically never changed.
The decoder-only transformer — stacked layers of multi-head attention plus feedforward networks, trained autoregressively on next-token prediction — has held up remarkably well. GPT-2 shipped with this architecture in 2019 and the core of it still runs in today's frontier models. That's a long time for anything in ML to stay relevant.
What GPT-2 got right was the simplicity of the setup. Autoregressive language modeling with a clean training objective scaled in a way that more complex pre-training schemes largely did not. The architecture was flexible enough to absorb a huge number of subsequent modifications without breaking. You can run RoPE through it, swap in GQA, replace the activation function — and the fundamental training loop stays intact.
The baseline was solid. The modifications were improvements on top of a working foundation, not rescues of a broken idea.
Positional Embeddings: From Absolute to RoPE
GPT-2 used absolute positional embeddings — each position in the sequence gets a learned vector that's added to the token embedding. Simple. Works fine at the sequence lengths GPT-2 was trained on.
The problem is that absolute embeddings don't generalize beyond the maximum sequence length you trained with. If you trained on sequences up to 1,024 tokens and try to run inference on a 2,000-token input, the model has no idea what to do with positions it has never seen. The representation is completely out of distribution.
This matters because the value of long-context models is real. Clinical notes are long. Legal documents are long. Codebases are long. A model that can't handle more than a couple thousand tokens without degrading is a significant practical limitation.
Rotary Positional Embeddings — RoPE, introduced in 2021 and now present in LLaMA, Mistral, DeepSeek, and most serious open-weight models — solved this differently. Instead of adding a position vector to each token, RoPE rotates the query and key vectors in attention by an angle that encodes relative position. The key property: the dot product between a query at position m and a key at position n depends only on the distance m - n, not on the absolute values.
That relative encoding is what enables length generalization. A model trained on 4,096-token sequences can, with appropriate fine-tuning or scaling techniques, handle significantly longer sequences because the positional relationship between tokens is the same whether you're at positions 10 and 20 or positions 10,010 and 10,020.
When a model claims to support 128K or 1M token context windows, RoPE — or a variant of it — is almost always the mechanism that makes that remotely feasible. Absolute embeddings can't get you there.
Attention: From MHA to GQA to MLA
Multi-head attention (MHA) as GPT-2 used it has a KV cache problem at scale.
During autoregressive inference, the model needs to store keys and values for every past token so it doesn't recompute them on each step. With MHA, every attention head maintains its own full KV cache. At large sequence lengths and large model sizes, this becomes the binding memory constraint. You're not limited by compute. You're limited by how much GPU memory the KV cache is eating.
Grouped Query Attention (GQA), adopted by LLaMA 2 and now standard in most serious open models, is the practical fix. Instead of each query head having its own unique K and V head, GQA groups query heads so that multiple query heads share a single K/V head. At the extreme, you get Multi-Query Attention (MQA) — all query heads share a single K/V pair.
The memory reduction is significant. In practice, GQA with 8 groups cuts KV cache memory by roughly 8x compared to MHA, with minimal quality degradation on most benchmarks. That means you can run longer contexts, larger batch sizes, or simply fit a model on fewer GPUs.
DeepSeek V2 and V3 pushed this further with Multi-head Latent Attention (MLA). It's a more sophisticated factorization where the K/V matrices are compressed through a low-rank bottleneck before being cached. The effect is similar: dramatically reduced KV cache size. But the mechanism preserves more expressiveness than naive GQA at the same compression ratio.
The trajectory is clear: MHA was the obvious first design, GQA was the practical scaling fix, MLA is a more principled version of the same insight. Each step is motivated by the same constraint — memory at inference time — not by theoretical elegance.
Activation Functions: The Quiet Move to SwiGLU
This one gets less attention than positional embeddings or attention variants, but it matters.
GPT-2 used GELU (Gaussian Error Linear Unit) in the feedforward layers. GELU is smooth, differentiable, and a significant improvement over ReLU for transformer training dynamics. It became a default for good reason.
SwiGLU, proposed by Noam Shazeer in 2020 and now ubiquitous in LLaMA, PaLM, and their descendants, is a gated variant that combines a Swish activation with a learned gating mechanism:
SwiGLU(x, W, V, b, c) = Swish(xW + b) ⊗ (xV + c)
The gating means the activation function is learned, not fixed. The network can modulate which features are amplified or suppressed at each position. Empirically, models trained with SwiGLU tend to converge to lower loss at equivalent parameter counts compared to GELU. The improvement isn't dramatic in isolation, but it compounds with scale.
There's a small implementation cost: SwiGLU feedforward layers use two weight matrices instead of one (hence the ⊗ gating), which means you need to reduce the hidden dimension slightly to keep parameter count constant when switching from GELU. Well-tuned implementations handle this automatically, but it's worth knowing if you're comparing architectures.
The broader point: activation function choice affects training dynamics more than most engineers realize. It's not just a nonlinearity. It's part of how gradients flow through the network during training. SwiGLU's adoption across essentially every serious modern architecture isn't coincidence.
What DeepSeek V3 Looks Like at the End of This Evolution
By the time you get to DeepSeek V3, you're looking at a model that has absorbed all of these architectural lessons:
- RoPE for positional encoding, enabling long context
- MLA for attention, dramatically reducing KV cache memory at scale
- SwiGLU in the feedforward layers for better training dynamics
- Mixture of Experts (MoE) for scaling parameters without proportionally scaling compute per token
That last one — MoE — deserves its own article. The point is that DeepSeek V3 represents a coherent set of engineering decisions, each motivated by a specific scaling constraint. It's not a collection of clever ideas. It's a systematic response to the problems that emerged as models got bigger and inference requirements got more demanding.
What Practitioners Actually Need to Know
I don't need you to understand every implementation detail. Here's the practical read:
These changes weren't aesthetic. RoPE enables long context. GQA/MLA reduces memory cost at inference. SwiGLU improves training efficiency. Every one of these was solving a real problem that was blocking scale or deployment.
When a new model claims "better architecture," you now know what questions to ask.
- How does it handle positional encoding? Can it generalize to longer sequences than it was trained on?
- What is the attention mechanism? What is the KV cache size at the sequence lengths you need?
- What activation function does it use in feedforward layers? Has it converged to SwiGLU or something newer?
- If it uses MoE: how many experts are active per token? What's the routing strategy?
These questions aren't academic. They determine whether a model will fit on your available hardware at the sequence length you need, how much memory your inference stack will consume, and whether the training dynamics have been validated at the scale you care about.
The field has converged on a handful of choices for good reasons. RoPE, GQA or MLA, SwiGLU — if you see a new open-weight model using all three, that's a sign the authors understand what they're doing. If a new model makes unusual choices in any of these areas, that's not automatically a red flag, but it should prompt questions. What problem were they solving that the standard choices didn't address?
Most of what will matter over the next several years won't be invented from scratch. It'll be the community identifying which of today's architectural choices were the GPT-2 equivalents — the pieces worth keeping — and which ones are still waiting for a better answer.
Understanding the evolution from GPT-2 to DeepSeek isn't history for its own sake. It's pattern recognition. The models that won didn't win because they were novel. They won because they were precise about which problems needed solving and disciplined about not breaking what was already working.
That's a pattern worth studying.