When Recommendations Meet Language: The LLM-RecSys Convergence
The retrieval paradigm is shifting under us
Here's a failure mode I hit while building MetaCaddie, the AI caddie I've been working on. A user is standing on a tee box and asks something like: "I'm 215 to the front, hazard left, wind in my face — what do you think?" The retrieval system would pull the relevant context — hole layout, the user's recent shot dispersion with each club, lie type, wind adjustment — by embedding similarity. The LLM would then try to reason about it. And somewhere in the handoff — between the system that understood shot patterns and the language model that understood the question — something would get lost.
The model would hedge. Or recommend a club without weighting the hazard correctly because the danger wasn't represented in the embedding the way the model needed to read it. Or give generic advice that ignored the user's actual tendency to push everything 10 yards right under pressure. The shot recommendation and the language understanding were happening in two separate systems, talking past each other.
This is a structural problem with how most teams build AI products today. The recommendation engine lives here. The language model lives over there. They're connected by prompts and API calls, not by shared understanding. Every seam is a place where quality degrades.
The Standard Architecture and Its Hidden Cost
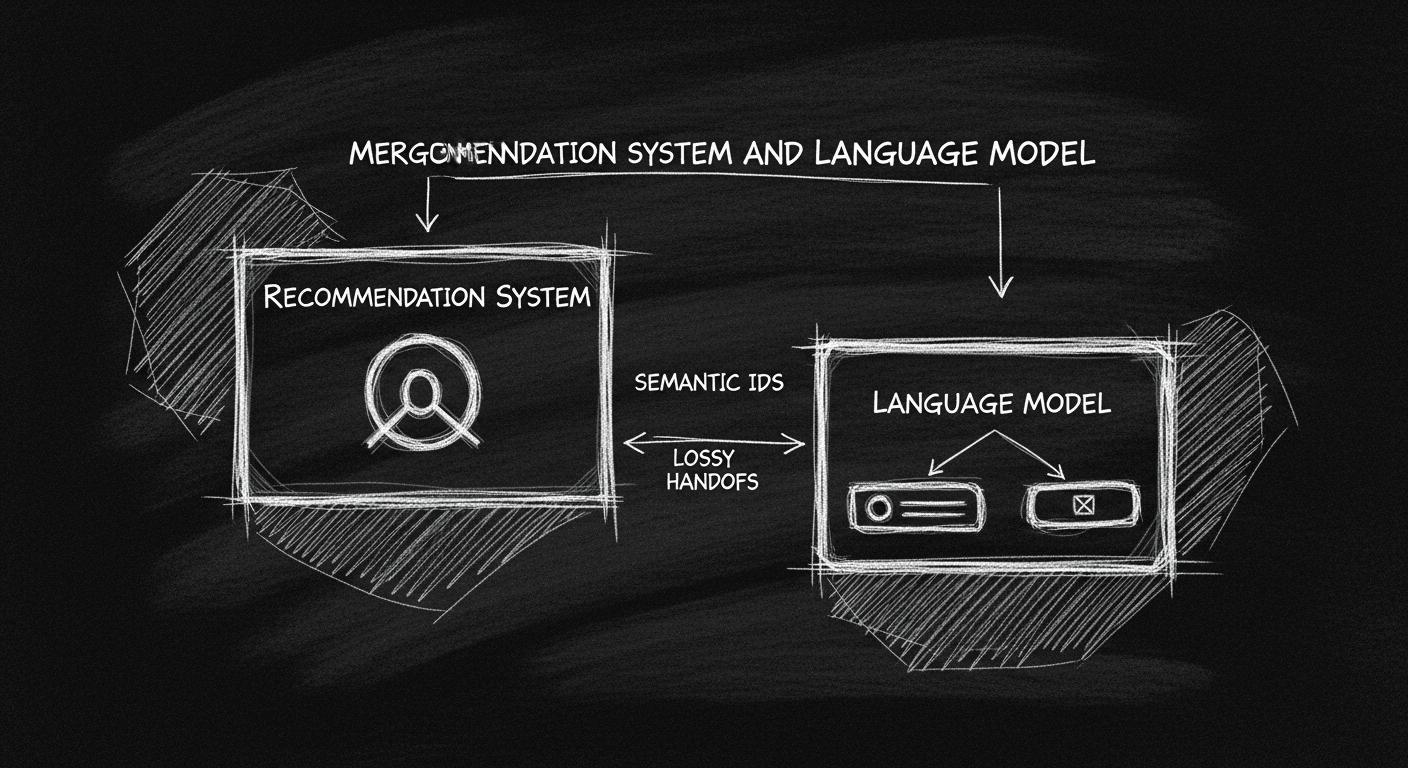
Most production AI stacks look something like this: a retrieval layer (vector database, collaborative filter, or traditional ranking model) surfaces candidate items, then a language model receives those candidates as context and generates a response. The two systems are independently trained. They share no vocabulary. The LLM has no native understanding of what "Course ID 4821" means — it just sees whatever metadata you've decided to pass along in the prompt.
This creates a cascade of problems. The retrieval system knows about items; the LLM knows about language. Neither knows what the other knows. The LLM can't steer the retrieval; the retrieval can't benefit from the LLM's reasoning about user intent. Personalization — factoring in what this specific user has done, preferred, and told you over time — requires duct-taping session context into a prompt and hoping the model pays attention.
The handoff is always lossy. You're doing a format conversion at exactly the moment when precision matters most.
The Insight: Teach the Model Your Domain Vocabulary
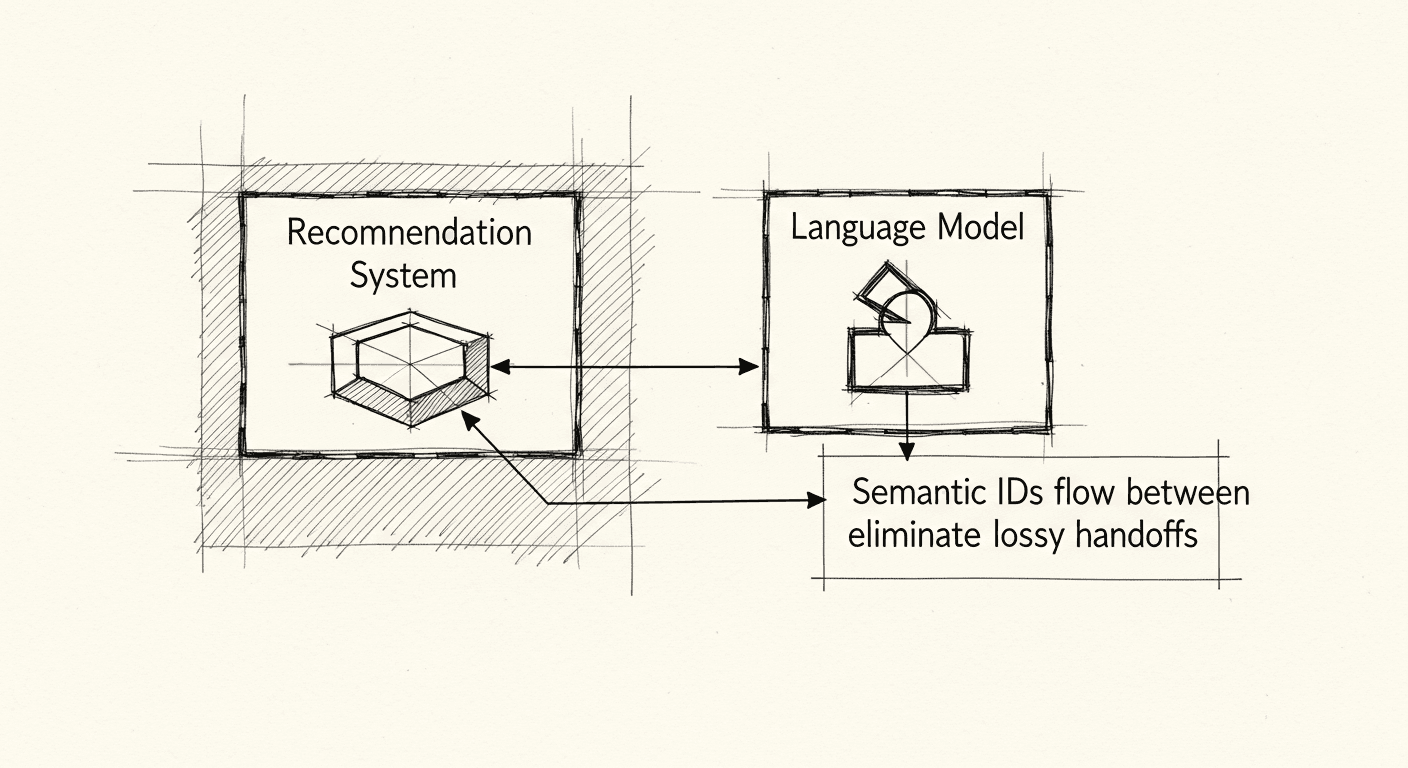
The emerging work on LLM-RecSys hybrids points at a different architecture, one that eliminates the handoff by expanding what the language model natively understands.
The core idea: create hierarchical semantic IDs for your domain items, and treat those IDs as first-class tokens in the model's vocabulary.
Instead of "Course ID 4821," you'd represent a golf course as a structured token like [desert][arizona][links-style][fast-greens][premium] — a hierarchy that encodes meaningful attributes at each level. The model's vocabulary is extended to include these domain tokens alongside natural language. You then train on data where natural language and item tokens appear together: user queries, course descriptions, playing histories, and the structured IDs that correspond to them.
What you end up with is a genuinely bilingual model. It can handle a sentence like "find me something like Troon North but more affordable" and reason directly about course tokens — not because you translated the query into a lookup, but because the model learned to think in both languages at once.
This isn't semantic search with a better embedding model. It's vocabulary expansion at the architecture level. The model doesn't retrieve items and then talk about them. It reasons about items the same way it reasons about words.
What This Unlocks
The practical implications branch in three directions.
Unified search and recommendations. Right now, "search" and "recommendations" are usually two separate systems with different codebases, different data pipelines, and different failure modes. A hybrid model collapses these into one. A query like "show me something I'd like" and a query like "find courses with fast greens in Arizona" go through the same model, which can combine semantic understanding with learned user preferences without routing between systems.
Steerable recommendations through language. This is the one that changes the user experience most visibly. Instead of a recommendation engine that surfaces items based on past behavior — offering no mechanism to tell it what you actually want right now — a hybrid model lets users steer in natural language. "Show me courses like what I usually play, but shorter — I'm playing with my dad this weekend." That instruction isn't a keyword filter. It's a behavioral override that the model can understand and apply against its learned representation of your history. The recommendation becomes a conversation.
Personalization that generalizes. Collaborative filtering breaks down for new users and long-tail items. It can only recommend based on behavioral co-occurrence, which requires volume. A model that understands the semantic structure of items can generalize across sparse data — it knows that a user who likes fast greens on desert courses probably also wants tight lies and low rough, because the semantic ID hierarchy encodes those relationships. You get cold-start behavior that's meaningfully better than "recommend the most popular items."
Applying This to Golf AI
MetaCaddie's recommendation problem is a good test case because golf is a domain with genuine complexity. A golfer's preferences aren't just about difficulty level or price. They're about course architecture style, pace of play, the kind of experience they want that day, their current form, who they're playing with. Collaborative filtering captures some of this from behavioral history. It captures almost none of the contextual nuance.
The semantic ID approach gives me a path to encoding that nuance structurally. A course isn't a blob of metadata. It's a hierarchy: region, terrain type, design philosophy, conditioning characteristics, pace category, price tier. Each level of the hierarchy is a token the model can reason about. When a user says "something more scenic, I'm in vacation mode," the model doesn't have to map that to a lookup. It can reason directly from the vacation-mode signal to the scenic-course region of its item vocabulary.
The training data for this isn't exotic. It's the natural language users already produce — round notes, reviews, questions, preference statements — paired with the course tokens that correspond to what they played and what they liked. The model learns the correspondence because it's trained to predict both.
The Healthcare Parallel
I've been thinking about this in the context of clinical decision support as well, because the structural problem is identical. A clinical guideline recommendation system and a language model for answering clinical questions are almost always two separate systems with a lossy handoff.
The semantic ID framing maps cleanly: clinical guidelines, drug classes, diagnostic codes, and treatment protocols all have hierarchical structure. A CDS system that could reason natively about [condition][diabetes-type-2][comorbidity][ckd][medication-class][sglt2-inhibitor] as a token hierarchy — alongside the natural language of the clinical question — would be fundamentally more capable than one that retrieves guidelines and then passes them as context.
The regulatory constraints are different and the stakes are higher, but the architecture problem is the same. Two systems with separate vocabularies, connected by a lossy prompt-formatted handoff.
What to Build With This
If you're running a domain-specific AI product today, the practical question is when this architecture becomes worth building versus the simpler retrieval-plus-LLM stack.
My current answer: when user intent is complex and contextual, when personalization matters and your item space has real semantic structure, and when you're hitting the ceiling of what retrieval-then-reason can do. For early products with limited training data, the standard stack is fine. For products where the recommendation quality gap is becoming a growth constraint, hybrid architecture is worth the investment.
The components you need aren't exotic. A hierarchical taxonomy of your items (which you should probably have anyway). A training set of natural language paired with item tokens — this is the hard part, building the labeled data. Fine-tuning infrastructure to extend a base model's vocabulary.
The last two years of open-source tooling have made all of this materially more accessible. What required a dedicated research team in 2022 is now a serious engineering project for a capable ML team. The question isn't whether this is technically feasible. It's whether you have enough training signal and enough product pain to justify building it.
For MetaCaddie, I'm convinced the answer is yes. The handoff between the recommendation system and the language model is the quality ceiling we're bumping against, and the path forward is collapsing the seam — not building a better bridge across it.
That's the architecture question worth thinking hard about.