You Don't Need GPT-4 for That: Small Models and Edge Agents

When the right answer is the model that never leaves the building
The default assumption when someone says "we need an agent that can call tools reliably" is GPT-4. Or Claude Opus. Or whatever the current frontier model is this quarter. Pick the biggest, smartest model and route everything through it.
I've made this assumption. I've watched teams spend six months defending it, paying frontier model API costs on every inference, and then hit a wall when they tried to deploy into an environment that couldn't make outbound API calls at all.
The BAIR research group published a paper called TinyAgent: Function Calling at the Edge that breaks this assumption cleanly. The finding: small open-source models, they tested a quantized 1B and 7B Llama, match GPT-4-Turbo on structured function calling benchmarks when they're fine-tuned on curated data. Not almost-match. Match, on the specific task of deciding which tool to call and how to call it.
That's a result worth understanding in detail, because it changes the architecture conversation significantly.
What TinyAgent Actually Showed
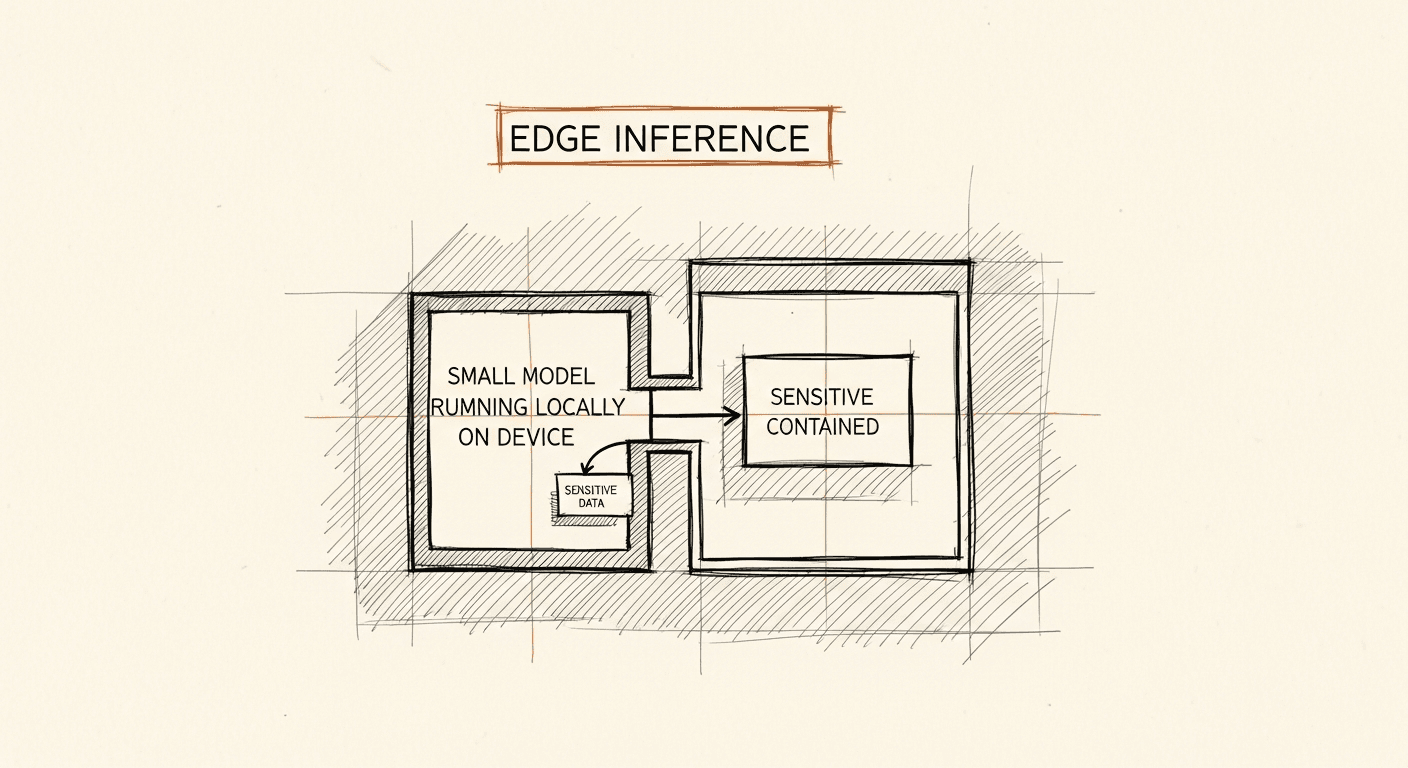
The researchers were solving a concrete problem: build an on-device agent for macOS that can execute multi-step tasks (send an email, create a calendar event, summarize a document) without routing any data to a cloud API.
The technical contribution was two-fold.
First, they built a function calling dataset and fine-tuned small Llama models on it. The key insight was data curation, not model scale. They generated high-quality (prompt, tool call) pairs covering realistic compound tasks: not toy examples, but multi-step sequences where the agent had to chain tools correctly. The fine-tuned 7B model matched GPT-4-Turbo's performance on their benchmark. The 1B model came close.
Second, they introduced Tool RAG: retrieval-augmented generation applied to tool selection. When you have dozens or hundreds of available tools, you don't inject all of them into the context window. You retrieve the relevant subset based on the current task. This solves a real problem. Small models degrade faster than large models when the context is overloaded with irrelevant information. Pruning the tool set to what's needed for the task lets the model reason clearly within its context budget.
The practical output: a quantized model running locally on a MacBook, with real-time latency, no cloud API dependency, and competitive accuracy on function calling tasks.
Why This Matters More for Healthcare AI Than Anywhere Else
Most of the commentary on on-device AI focuses on cost and latency. Both are real benefits. But in healthcare, there's a third dimension that's non-negotiable: data residency.
PHI, protected health information, is governed by HIPAA. Under HIPAA, sending patient data to a third-party API requires a Business Associate Agreement with that vendor. Most frontier AI providers offer BAAs, but that's not the end of the compliance analysis. Your security team will ask where the data is processed, whether it's used for training, how long it's retained, and what breach notification procedures look like. Some healthcare organizations, particularly those operating in certain hospital systems, VA contexts, or with particularly conservative compliance postures, prohibit sending patient data to cloud APIs entirely, regardless of BAA status.
If you've built your agent on a cloud API dependency, you've just built something that cannot be deployed in those environments.
Edge models remove this constraint at the architecture level. If inference runs on-device or within the organization's own infrastructure, PHI never leaves the perimeter. There's no API call to audit, no retention policy to negotiate, no third-party data processor to add to your BAA inventory.
This isn't a nice-to-have. For some healthcare AI deployments, it's the only path to production.
What "Good Fine-Tuning Data" Actually Means for Function Calling
The TinyAgent result, small models matching frontier models on this task, depends entirely on data quality. That's the lever. And "high-quality fine-tuning data" is one of those phrases that sounds specific but usually isn't.
For function calling specifically, here's what it actually means:
Realistic task variety, not toy coverage. A function calling dataset built on simple single-tool invocations will produce a model that fails on multi-step tasks. The training data needs to cover the compound cases: tasks that require sequencing tools, tasks where intermediate results feed into subsequent calls, tasks where the right answer is to call no tool and return a clarification request. If your agent will live in a clinical documentation workflow, your training data needs examples from that workflow, not generic assistant tasks.
Correct negative examples. Most function calling datasets underrepresent the cases where no tool should be called, or where the model should reject an ambiguous request. A model that's only seen successful tool calls will hallucinate tool invocations on out-of-distribution inputs. Include examples of appropriate refusals and clarification requests.
Structured, schema-consistent outputs. Tool calls are JSON. JSON with optional fields, nested structures, and type constraints. Your training data needs to consistently represent the correct schema, not close approximations of it. One of the fastest ways to get a broken function calling model is to train on data where the same tool is invoked with inconsistent parameter names across examples. The model learns the variance, not the schema.
Coverage of your actual tool set. This sounds obvious and gets skipped constantly. A model fine-tuned on generic tool call data and then handed your specific API schemas will behave unpredictably on edge cases in those schemas. Generate fine-tuning examples that cover your actual functions, including their error cases and boundary conditions.
The generation workflow I'd use: start with a frontier model to generate (task, tool call) pairs across your tool schemas, then run automated validation, does the generated call parse correctly against the schema? Does it use the right parameter types? Filter aggressively. Fifty thousand noisy examples will underperform ten thousand clean ones.
When a 7B Model Is the Right Call
The short version: when the task is structured, the tool set is well-defined, and privacy or latency requirements make cloud APIs impractical.
Function calling is a structured task. The model needs to classify intent, select the correct tool, and produce a valid JSON invocation. This is not a task that requires broad world knowledge, multi-hop reasoning over ambiguous inputs, or creative generation. It's a pattern-matching and schema-adherence problem. A fine-tuned small model can solve it better than a general-purpose frontier model that's never been specifically trained on your tool schemas.
The use cases where I'd default to a small fine-tuned model for agents:
- Clinical workflow automation where PHI cannot leave the perimeter and the task set is bounded (schedule, document, retrieve, route)
- On-device personal health applications where the agent operates on the user's own device with no server dependency
- High-frequency, low-latency automation where API round-trip times matter — local inference at a quantized 7B runs in hundreds of milliseconds, not seconds
- Air-gapped or constrained deployment environments where internet connectivity cannot be assumed
The Tool RAG piece matters here too. If your agent needs to select from a large catalog of tools but typically uses a small subset per task, building the retrieval layer upfront keeps your small model operating cleanly. Don't try to cram 80 tool schemas into a 7B model's context window and wonder why it starts confusing similar tools.
When You Actually Need a Frontier Model
This is where the nuance lives, and where I see people overcorrect after they read results like TinyAgent.
Small fine-tuned models are good at the task they were fine-tuned on. They're brittle outside it.
If your agent needs to handle novel, open-ended tasks that weren't represented in training, reasoning about a new document type it's never seen, handling a request that combines tools in an unanticipated sequence, recovering gracefully from a partial failure in a multi-step plan, a frontier model's general capability is the safety net. The fine-tuned small model doesn't have one.
Frontier models are also still significantly better at:
Complex multi-hop reasoning. Decomposing a goal into subtasks, tracking intermediate state across a long execution, and adapting the plan when something unexpected happens: this is where scale still wins. The TinyAgent benchmark is function call accuracy. It doesn't test the harder planning problem of deciding which functions to call and in what order to achieve a goal the model's never seen before.
Edge case recovery. When a tool returns an error or an unexpected result, a frontier model is more likely to reason correctly about what happened and what to do next. Small fine-tuned models tend to get stuck in retry loops or produce off-schema calls when they encounter outputs that weren't in the training distribution.
High-stakes disambiguation. When the right tool call is genuinely ambiguous and getting it wrong has real consequences, routing a patient to the wrong care pathway, for example, the added reasoning capacity of a frontier model is worth the cost and latency.
The architecture I'd design for most healthcare AI agent work: a small fine-tuned model for high-frequency, well-defined tool calls where data must stay local, and a frontier model available as an escalation path for tasks that fall outside the defined scope. Not either/or. Both, with clear routing logic between them.
The Practical Decision Framework
Before you default to GPT-4 for your next agent, answer these questions:
Is the task structured? Does the agent need to call tools with defined schemas, or does it need to reason broadly about open-ended inputs? Structured tasks are fine-tuning candidates. Open-ended tasks probably aren't.
Can the data leave the perimeter? In healthcare contexts especially, this question should come first. If the answer is no, on-device or on-prem inference is not optional.
Do you have the fine-tuning data to make it work? Or can you generate it from your actual tool schemas? If you don't have the data discipline to build a clean fine-tuning set, you'll spend more time fixing a broken small model than you'd have spent paying frontier API costs.
What does failure look like? A fine-tuned small model that encounters out-of-distribution input will fail more abruptly than a frontier model. Know your failure modes before you choose your model tier.
TinyAgent is a proof of concept that should shift your defaults, not an argument that small models can do everything. The shift it justifies: "we need the biggest model available" is no longer a safe assumption for function calling tasks. The correct default is: "what's the minimum capable model for this specific structured task, given our constraints?"
In healthcare AI, those constraints often make the answer obvious. The hard part is doing the data work to back it up.