Tagged: fine-tuning
3 articles on fine-tuning.


Fine-Tuning a 70B Model on a Consumer GPU: The Q-LoRA Practical Guide
Q-LoRA + SFTTrainer + Flash Attention v2 means you can fine-tune a 70B parameter model on 24GB of VRAM. What that looks like end-to-end, what it costs in quality, and when to just use the API instead.
EngineeringRead more →

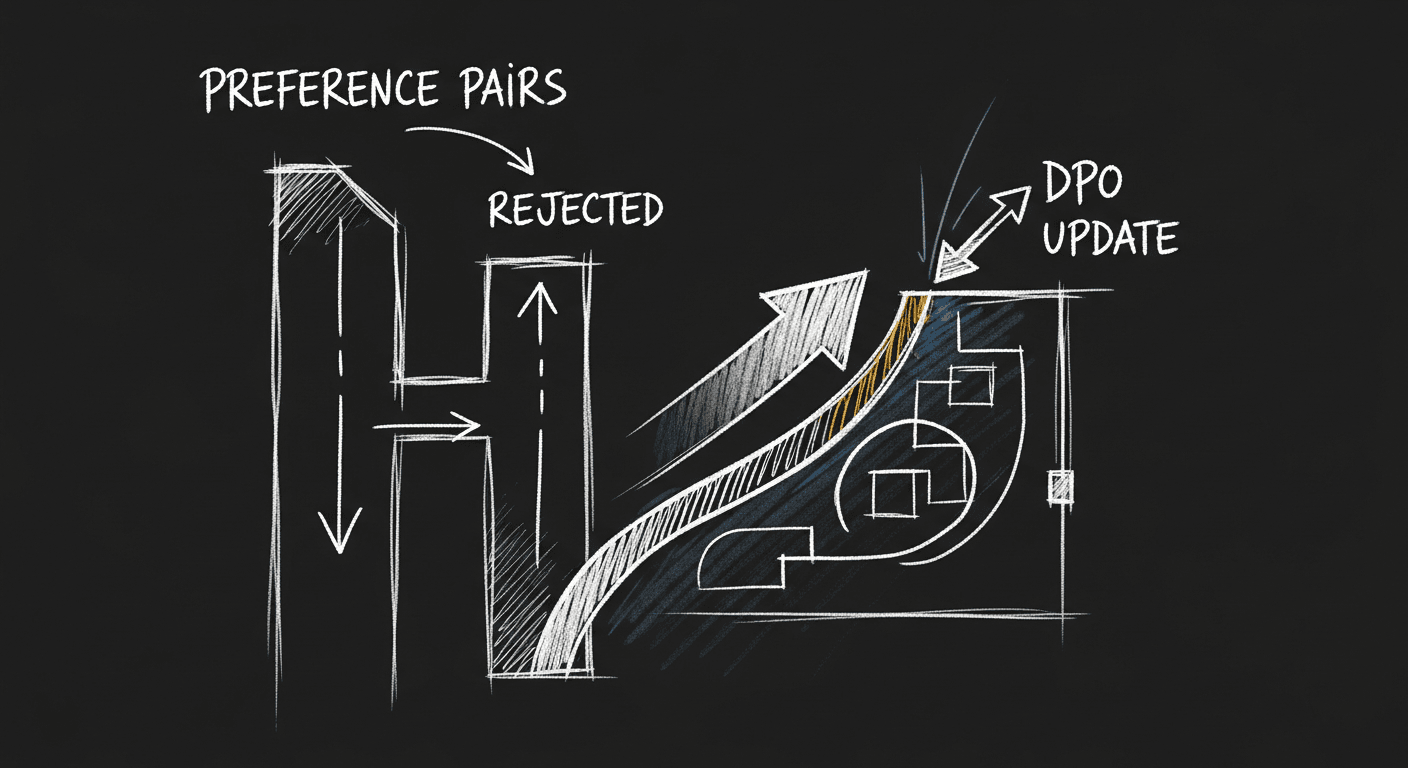
Fine-Tuning LLMs Without the RLHF Headache: The DPO Approach
RLHF is the right idea with the wrong implementation cost for most teams. DPO flips the math. How to align a healthcare AI model on clinician feedback without burning a month on reward model engineering.
EngineeringRead more →
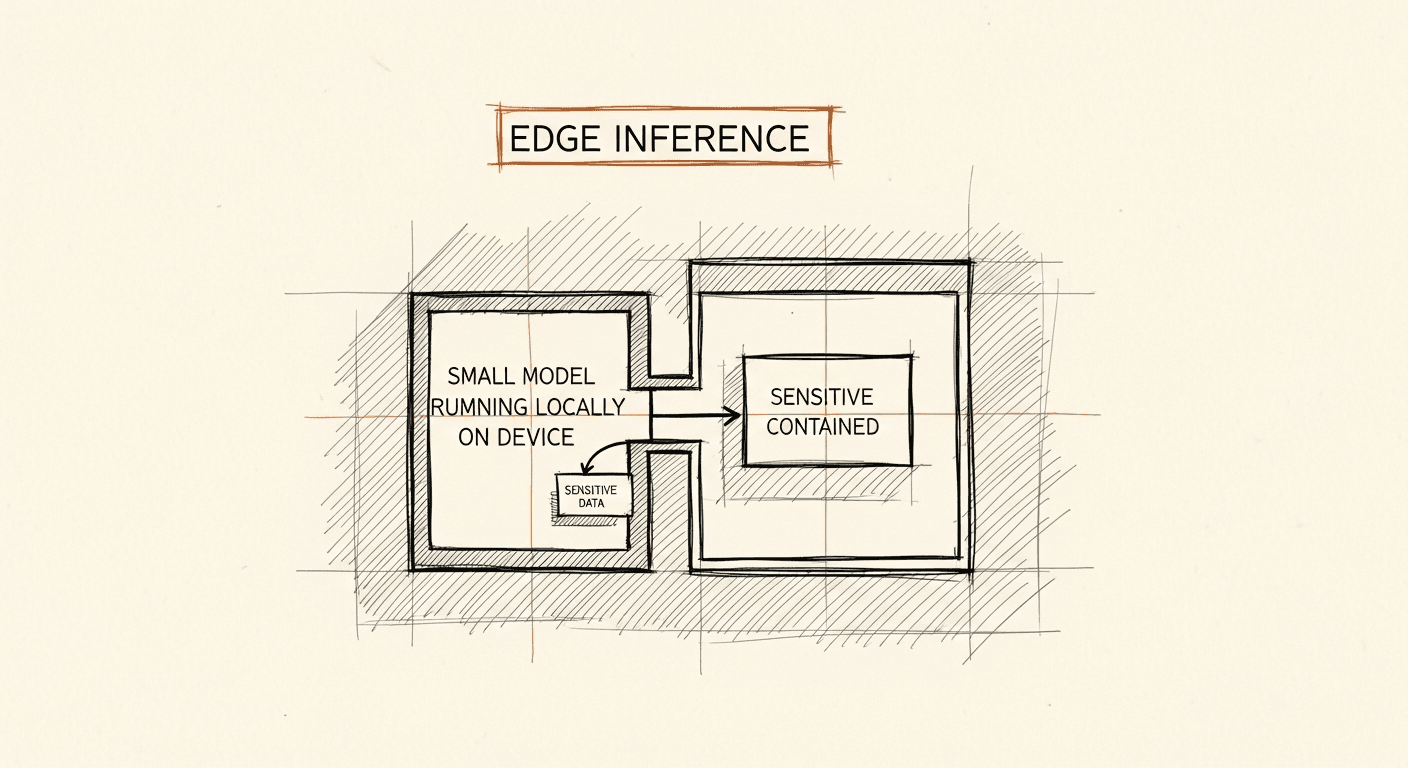

You Don't Need GPT-4 for That: Small Models and Edge Agents
Frontier models aren't required for agentic function calling. For healthcare AI, assuming they are can also be a compliance liability. When a fine-tuned 7B model is the right architecture, and when it isn't.
EngineeringRead more →