What AI Agents Actually Are (And What They Can't Do Yet)
The precise definition. Not the hype.
Most things called "agents" right now are not agents. They're a model call, maybe two, wrapped in a while loop and branded with a good demo. I've built enough of them, in healthcare AI, in golf AI, in enterprise ops tooling, to know the difference between a system that actually reasons and acts autonomously and one that's just an API with extra steps.
The distinction matters because they fail differently, require different design decisions, and solve different problems. If you're building the wrong thing for your problem, you'll hit a wall and blame the model when the real issue was architecture.
The Precise Definition
The cleanest framing I've found: an AI agent is an autonomous system that uses a foundation model as its reasoning engine. The key word is autonomous. The system perceives a state, decides what to do, takes action, observes the result, and iterates. It doesn't just answer a question and hand the output back to you.
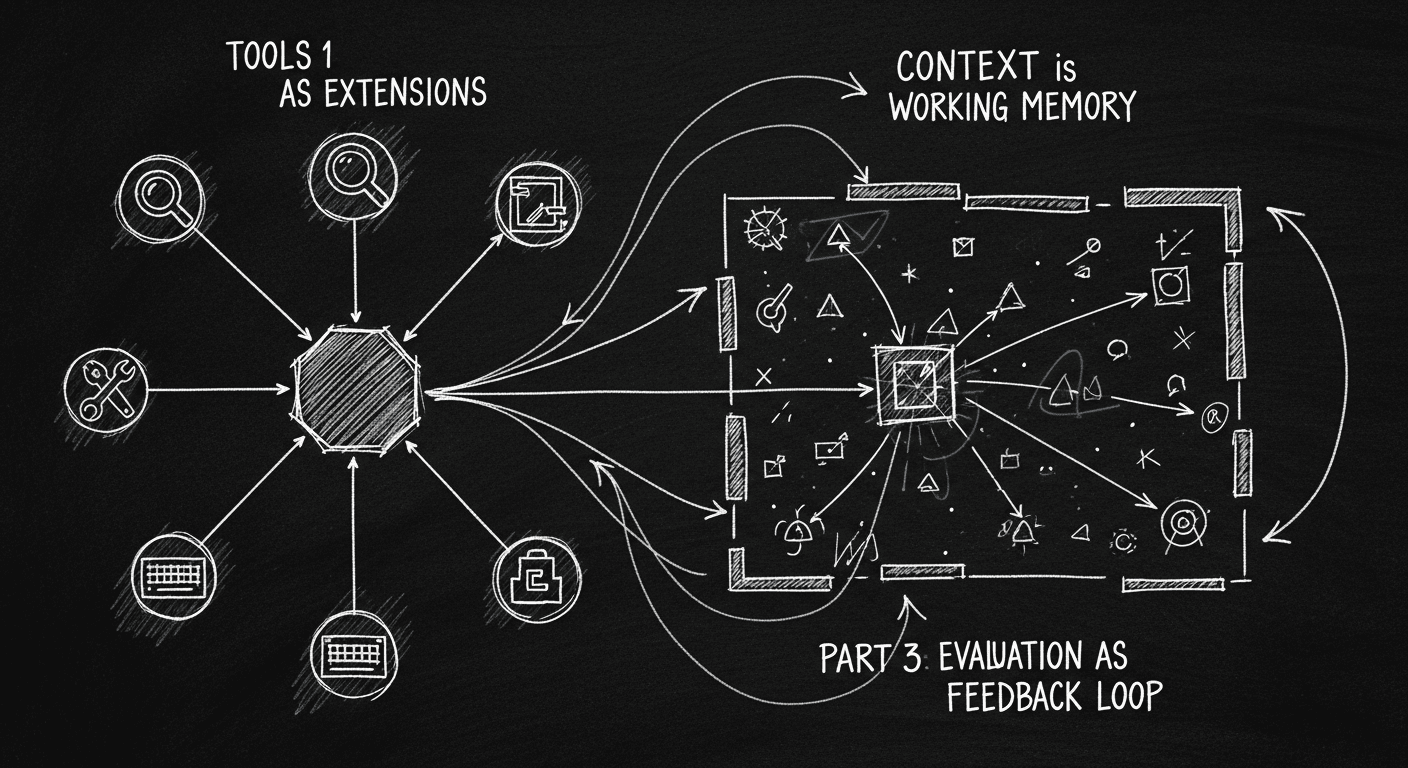
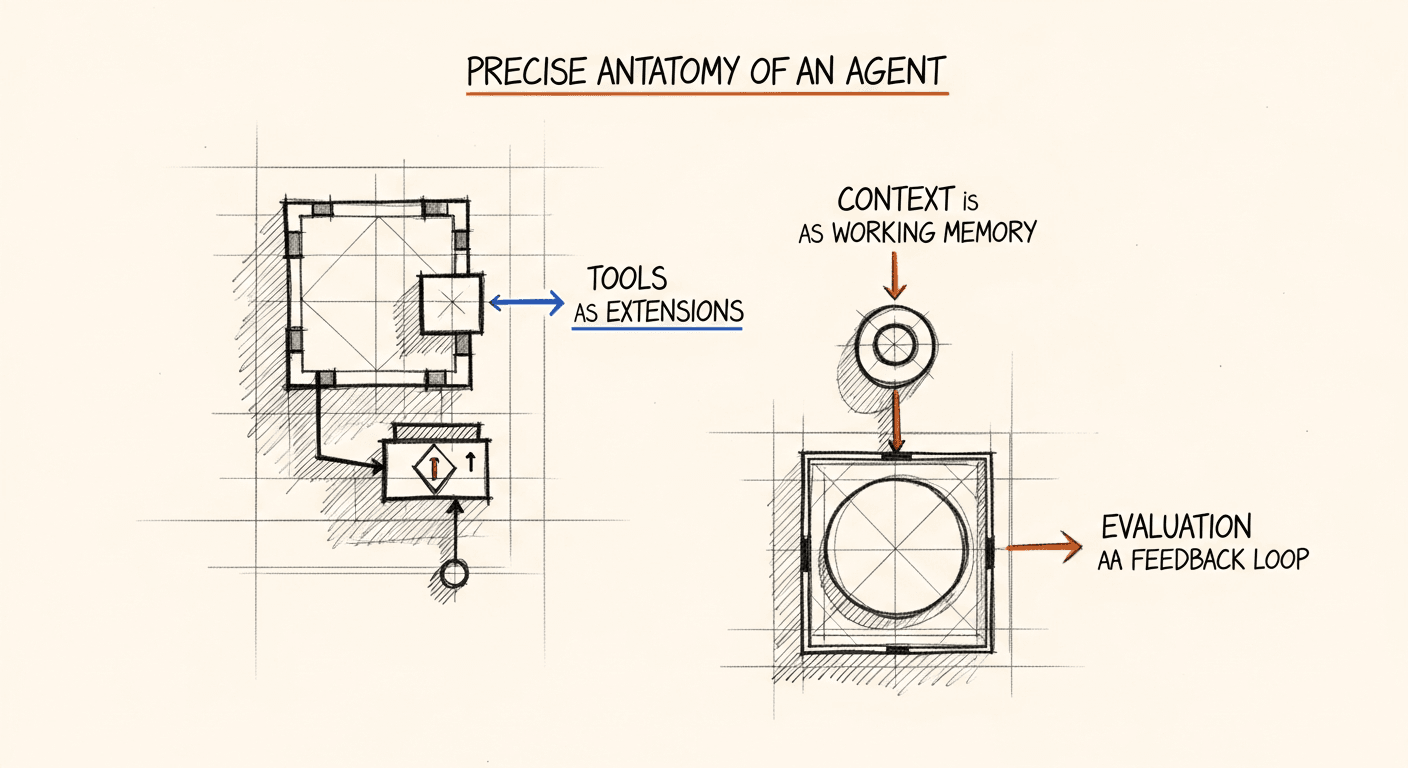
What that looks like in practice: the agent has a goal, a set of tools it can invoke, and a planning loop that runs until the goal is satisfied or it determines the goal is unreachable. It decides when to call which tool, what to pass it, and how to interpret the result, all without you specifying the sequence ahead of time.
A chatbot that calls a function to look up a customer record is not an agent. It's a function-calling interface. An agent would look up the record, notice something anomalous, decide to cross-reference another system, form a hypothesis about the anomaly, and surface a finding with reasoning attached, without being told to do any of those intermediate steps.
What Actually Determines Agent Capability
There are two levers: tool availability and planning strategy. Most people obsess about the model and ignore both.
Tool Design Is the Dominant Variable
Your agent can only do what its tools let it do. This sounds obvious. It isn't, because people design tools too narrowly.
The failure mode I've seen most often: an agent with a "search" tool that takes a query string and returns a flat list of results. That works for simple lookups. It breaks down when the agent needs to explore: to understand what else is in the space beyond the top five results, to filter by facets, to know when it's hit the edge of what's available. A better tool returns structured results plus metadata about the result space. Counts, categories, a signal about coverage. It gives the agent peripheral vision.
In clinical workflows, this matters enormously. I've built agents for prior authorization that could look up formulary data, read clinical guidelines, and check patient history. The ones that worked had tools designed around the decision the agent needed to make, not around convenient API boundaries. The ones that failed were exposing raw FHIR endpoints and expecting the model to figure out the data model. Tool design is the difference.
Design tools around agent reasoning, not backend convenience. Ask yourself, what does the model need to know to decide its next move? and build the tool response to answer that question directly.
Planning Strategy Determines What Complexity You Can Tackle
Planning is not just "chain-of-thought prompting." It's the structural pattern your agent uses to decompose and execute work.
Three patterns I actually use:
ReAct (Reason + Act): The model alternates between reasoning about what to do and taking an action. Good for tasks where the right path is mostly linear but requires adapting based on tool results. Most single-agent tasks fit here. It's interpretable, debuggable, and doesn't require anything exotic.
Plan-then-Execute: The agent first constructs a complete plan, a DAG of subtasks, then executes it. Better for tasks where you can anticipate the structure of the problem upfront and need to parallelize. The risk: plans go stale. If step three's output changes what step five needs to do, a rigid plan fails. Build in re-planning checkpoints.
Multi-Agent Orchestration: An orchestrator agent decomposes work and dispatches it to specialized subagents. Each subagent has a narrower scope and a tighter tool set. This is the right pattern when tasks are both parallelizable and heterogeneous, where different subtasks need different capabilities. It's also the hardest to debug because failures can be silent and cascading.
Pick the simplest pattern that fits your problem. ReAct handles 80% of what I've needed to build. Orchestration gets introduced when I've already confirmed ReAct is genuinely insufficient, not as a starting point because it sounds more impressive.
What Agents Can't Do Yet
I've hit three failure modes repeatedly.
Long-horizon coherence. Agents degrade over long task sequences. The model drifts from the original goal, accumulates context that crowds out earlier instructions, or loses track of what it has already tried. For clinical workflows with many decision branches, this is a real ceiling. My current mitigation: explicit state checkpointing and injecting summaries of prior work rather than letting the full raw trace accumulate.
Knowing when to stop. Agents are optimistic. They will keep trying when a human would recognize the task is underdetermined and ask for clarification. In healthcare, this is dangerous. An autonomous system that fabricates a plausible-looking prior auth justification because it doesn't know how to say "I don't have enough information" is a liability, not a feature. Build explicit confidence thresholds and design human escalation paths as first-class system components, not afterthoughts.
Tool failure handling. Real tool calls fail. APIs time out, data is missing, a query returns nothing. Agents trained on happy paths handle this poorly: they either retry in a loop or confidently proceed with bad data. I test every agent against a failure-injected version of its tool set before shipping. It's the single most revealing test you can run.
How to Pick the Right Pattern
Start here: is the task fundamentally sequential or does it require genuine exploration?
If the sequence of steps is mostly knowable upfront, use ReAct. Write clear tool descriptions, test with real inputs, review traces. You're done.
If the task requires the agent to discover what to do next based on what it finds, you need richer tools: ones that return enough context for the model to orient itself within the problem space. The model tier matters less than most people think. A mid-tier model with well-designed tools consistently beats a frontier model with bad ones.
If the task is genuinely too large for a single context window, or requires truly parallel independent subtasks, reach for orchestration. But be honest: orchestration adds coordination overhead, failure surface, and debugging complexity. Only introduce it when the alternative is provably worse.
The question I ask before every agent build: what decisions does this agent need to make, and what information does it need to make each one? Work backwards from the decisions to the tools. Work backwards from the task complexity to the planning strategy. The model is the last variable I tune.
People keep asking me whether agents are ready for production in regulated industries. In healthcare, my answer is: for specific, bounded tasks with clear success criteria and human oversight in the loop, yes. For open-ended clinical reasoning without a human review step, not yet. The gap isn't model capability. It's that agents still don't know what they don't know. Until that changes, the human in the loop isn't a workaround. It's the architecture.
Build accordingly.