Articles · Page 5
Older posts from the archive.
The Self-Healing Stack: What AI-Native Infrastructure Actually Means
The AI Cloud vision, where infrastructure monitors, optimizes, and repairs itself, is compelling. Some of it exists today. Most doesn't yet. What self-healing infrastructure looks like in practice, and what engineers should be doing to prepare.
FHIR Meets Graph Databases: Exploring Healthcare's Natural Network Structure
FHIR data is a graph. Treating it as flat tables is why most healthcare AI struggles with relationships between patients, providers, and encounters. What happens when you model it the way it actually is.


The Tools I Dropped When AI Changed My Development Workflow
AI coding assistants forced a full rethink of every layer of the dev stack. What I dropped, what I added, and the principle behind the restructuring.
From GPT-2 to DeepSeek: The Architectural Changes That Actually Mattered
I've been reading ML papers for 10 years. Most don't matter. These architectural choices did. RoPE, GQA, SwiGLU: each one solved a real scaling problem. What to look for when a new model claims 'better architecture.'

Building a GenAI Platform That Doesn't Collapse Under Its Own Weight
GenAI platforms don't fail because the models are bad. They fail because teams build everything at once. A practitioner's guide to layered architecture, from the minimal production-ready core to healthcare-grade guardrails.

The GenAI Strategy Question You're Not Asking (But Should Be)
Everyone asks 'how should we use GenAI?' The honest answer requires a harder question: does AI's unique capability create new value here, or is it just a more expensive way to do something that already worked? A practitioner's framework for getting this right in healthcare.

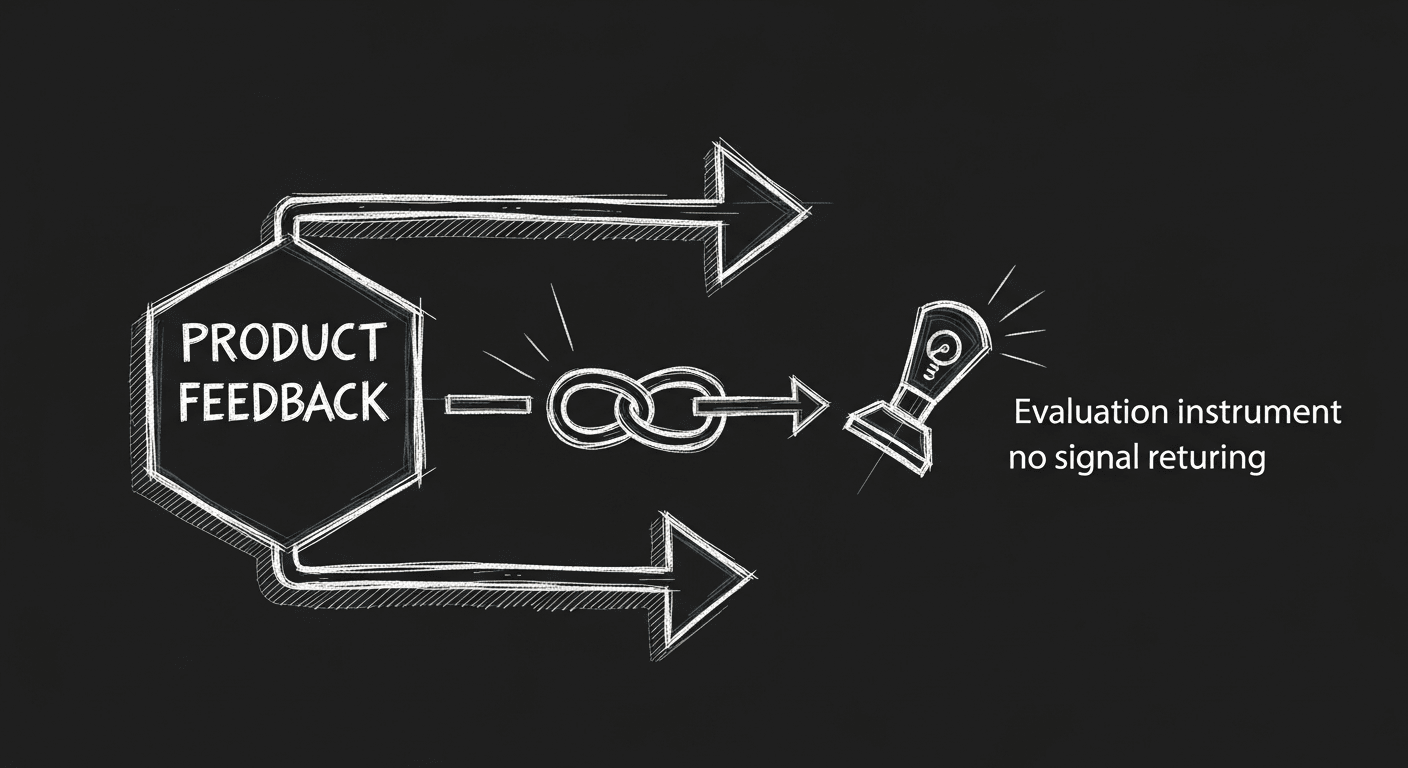
Every Failed AI Product Has the Same Root Cause
The same failure pattern shows up everywhere: teams shipping fast and iterating on vibes instead of building systematic evaluation. Evals aren't a nice-to-have. They're the core competency of any serious AI product team.


The 6 Ways I've Watched GenAI Projects Fail (And How to Avoid Them)
GenAI projects in healthcare go sideways in predictable ways, sometimes with real patient consequences. Six failure modes that come up over and over again, and what to do instead.


When to Look Beyond Standard LLMs (And When to Stop Overthinking It)
Most teams should use a frontier API and move on. There are specific situations where alternative architectures matter: extreme latency, long-context scale, cost walls, privacy constraints. The decision framework.