Inside a Production Voice Agent: How the Stack Actually Ships
The stack the production voice-AI teams have converged on.
Production voice-AI has settled into a shape.
The teams shipping reliable outbound agents in 2026 — the ones whose calls actually convert, whose compliance holds up under audit, whose end-to-end latency stays under two seconds across ASR, LLM, and TTS combined — have converged on the same architectural pattern. It is not the pattern most demo decks show. It is not a monolithic prompt with a tools array attached. It is not a chain or a router with branches. It is a graph: discrete conversational nodes, each holding a separated decision-prompt and response-prompt, stitched together with reusable subgraphs for repeating choreographies like voicemail detection and warm transfer.
I have spent enough time around production voice-AI builds over the last year — open-source frameworks like Pipecat and the LiveKit Agents ecosystem, hosted platforms with public architecture writeups, and enterprise teams running their own homegrown stacks in regulated industries — to be convinced this convergence is not a coincidence. The teams that have shipped real agents and lived through the QA cycles, the production A/B regressions, the late-night incident calls about an agent that disappeared mid-conversation, all end up at roughly the same architecture. The hosted platforms expose less of it; the open-source frameworks expose more. This piece is the synthesis: what the stack looks like, why it looks that way, and what most voice-AI teams are still missing.
What is below is voice-shaped — the constraints, the components, the failure modes. But the architecture and the evaluation discipline are not voice-specific. If you are building any domain-specific AI agent — a clinical decision support tool, a golf caddie like MetaCaddie, a continuous care monitor like MetaVigil, a coding agent — the same shape applies. Read what follows with the substitutions in your head; the closing section maps the patterns back out explicitly.
Why the graph
The first thing every mature voice-AI team does is throw away the monolithic prompt.
It happens early. You start with one big system prompt that says: greet the user, confirm identity, collect intent, book if they want, transfer if they want, opt out if they ask. You run it. The first ten test calls look fine. Then you run a hundred and the failure modes start showing up. The agent emits a tool invocation as content — the function name and arguments printed verbatim into the spoken audio. It enters loops on edge cases the prompt did not anticipate. It cheerfully agrees to schedule for a wrong-number caller. It freelances its own version of the compliance disclosure.
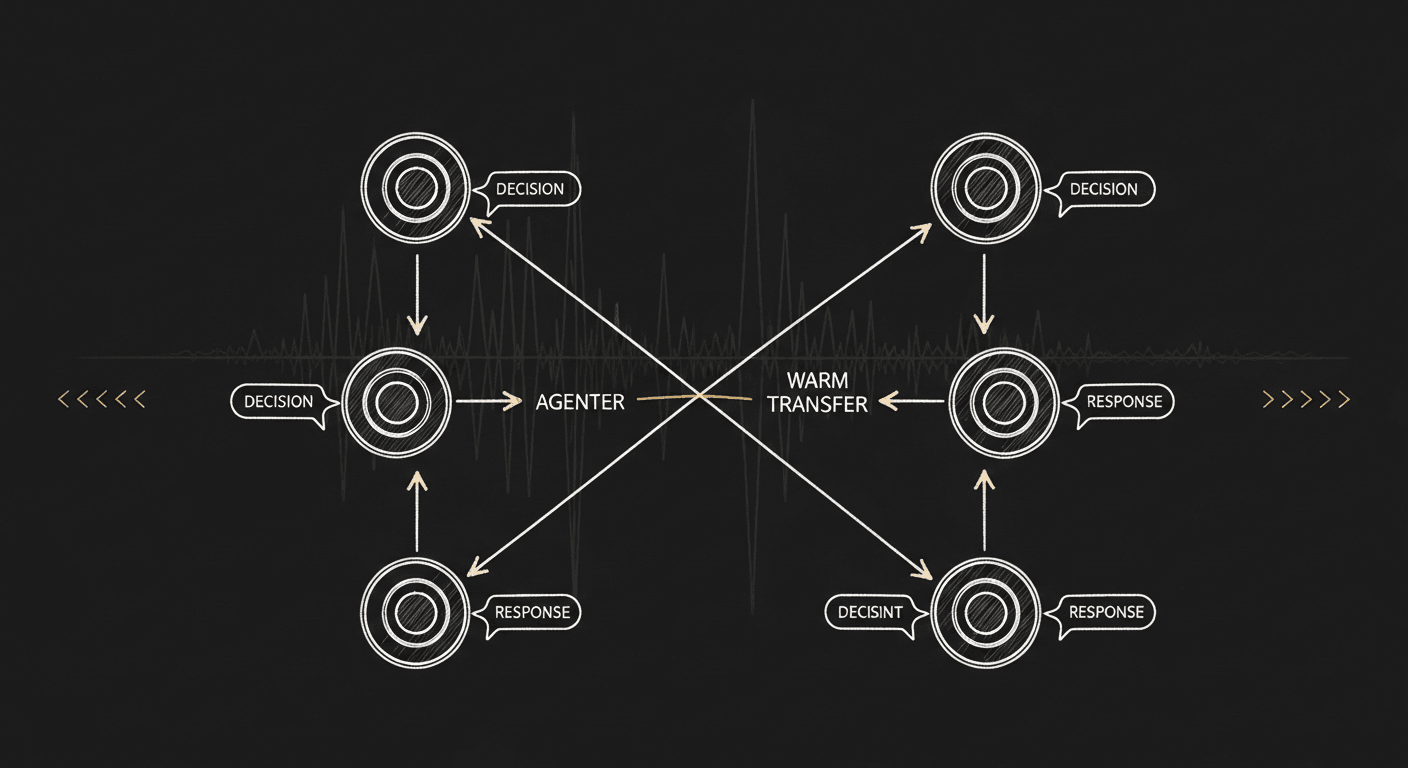
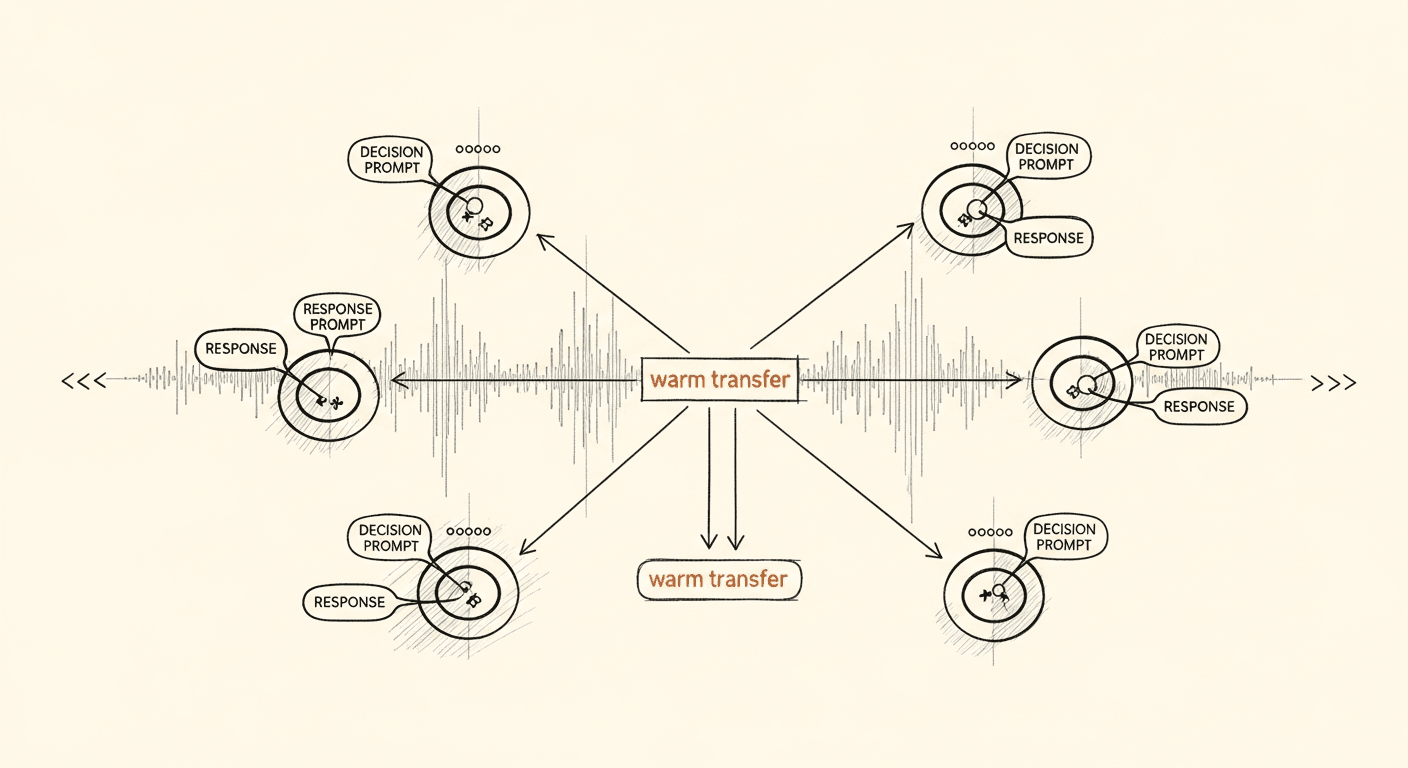
The graph is the answer to this. A graph-based agent breaks the conversation into discrete nodes, each representing a stage of the call. At each node the agent has a small, fixed set of tools it can call — confirm-identity, capture-intent, book, transfer, decline-and-opt-out, wrong-number, and a handful of similar — and routing from that node is determined entirely by which tool fires. Reusable choreographies — machine detection, voicemail, warm transfer, booking — live in subgraphs that can be parameterized and dropped into any new agent.
This sounds like overengineering until you try to add a new behavior. A missing wrong-number tool is a canonical failure mode: the caller says "you have the wrong person," and the agent — having no node that handles this — falls into a hallucinated apology loop, never actually ending the call. The fix is a few minutes of work: add a wrong-number tool with a description, declare its overlap-resolution rules against the adjacent not-the-client tool, register it on every node where it could fire, and wire up a post-call disposition for it. The fix is fast precisely because the architecture treats every conversation branch as a first-class addressable thing.
Decision prompts and response prompts are different prompts
The next thing mature teams do is separate the decision prompt from the response prompt.
Two LLM calls inside one node. Decision on the left, response on the right.
Inside a node, two LLM calls happen, not one. The decision prompt is small, focused, and sees only the tool list, the conversation context, and instructions on when each tool fires. Its only job is to pick a tool. The response prompt is also small, also focused, and only sees what is needed to generate the spoken response after the routing decision has already been made.
The reason for the separation is simple: you cannot reduce hallucination, latency, and cost simultaneously in a single monolithic prompt. Prompts that are doing many things at once produce inconsistent tool calls, inconsistent responses, and predictably slow inference. Splitting the work makes each prompt smaller, faster, easier to reason about, and — crucially — separately model-routable. Most teams running this pattern in production assign smaller, faster models to simple response nodes ("Got it, let me find a time that works for you") and reserve their best decision-making models for the routing nodes where a mistake means the call goes to the wrong place.
The other discipline that emerges here is hard separation between deterministic and inferred logic. If a fact is already in the call context — a parameter passed at call start, an argument collected from a prior tool call — you do not ask the LLM to use it conditionally. You inject it deterministically with a template. A two-line conditional in your template language beats a sentence of natural-language instructions every time: it cannot misroute, it cannot hallucinate, and it costs zero tokens. Natural-language conditional reasoning is reserved for the genuinely ambiguous cases. Everything else is a template.
This sounds pedantic. It is not. Each conditional you push out of the natural-language prompt is one fewer thing the model can get wrong, one fewer hallucination surface, and a measurable reduction in prompt size — which translates directly to lower latency on every turn.
The build pipeline runs on its own configuration
Mature teams build agents from configuration, not from a UI.
This is a counterintuitive choice. Plenty of voice-AI vendors lead with no-code or low-code editors. The teams shipping serious production agents have, with rare exceptions, abandoned them. The reason is that production-grade agents have so many small decisions — overlap-resolution between similar tools, conditional state injection, post-call disposition mapping, mid-call writes back to the customer CRM — that a UI either flattens the decisions out of view or buries them three menus deep. Configuration as code keeps them visible, diffable, reviewable. Open-source frameworks like Pipecat have settled on this from the start; the more mature hosted platforms have grown into it.
What changed in the last year is that the configuration is now mostly written by AI coding tools. The pattern that works: keep a stable framework-instructions document — schemas for nodes, tools, subgraphs, dispositions, and mid-call data updates — and a per-agent requirements document capturing the PRD. A coding agent reads both and produces, iteratively, a Mermaid graph design for human review before a single prompt is written; then a schema-only scaffold of nodes, tools, and dispositions; then the decision and response prompts authored against that scaffold; then the mid-call CRM writes and the post-call dispositions that the analytics pipeline consumes.
The non-obvious bit is the human review at the graph stage, not the prompt stage. Reviewing prompts is the wrong unit of review; by then the architectural shape is already locked in. Reviewing the graph is reviewing the agent's behavior at the only level that actually matters.
Text-based testing fails loudly
Every mature voice-AI team has built or bought a text-based simulator that exercises the entire compiled agent configuration without ever hitting an ASR or TTS — pure text in, pure text out, every tool call and routing decision visible turn by turn. Pipecat exposes a version of this in its flow framework; LiveKit Agents leans on it for development; in-house frameworks usually grow one within the first few months once teams realize how much time they lose iterating through audio. The crucial property: when the configuration is malformed, the simulator refuses to initialize the agent. A bad node schema, a missing tool reference, an unresolvable template path — all of these throw at construction time. This is the inverse of what monolithic-prompt systems do, where a misconfigured agent still happily generates responses, just wrong ones.
The other crucial property: sessions in the simulator can be captured as unit tests with one click. The test records the initial graph state, the user turn, and the expected output — which tool was called, what disposition was assigned, whether the end-of-call flag was set, what the response text contained. These captured tests run on every PR, alongside the framework's own unit tests for core components. A team running this pattern at scale will accumulate hundreds of captured tests over a few years.
A subtle point worth flagging: the captured tests are state assertions, not LLM-graded evaluations. The LLM-as-judge work happens in voice-to-voice testing, which is a different process running on a different schedule.
Voice-to-voice testing is where regressions actually get caught
The part most teams underinvest in is automated voice-to-voice testing — sometimes called V2V, sometimes agent-to-agent, sometimes synthetic-call testing. The label varies. The discipline does not.
The shape: you build a small population of LLM-driven human personas, each with reference data (a name, an income, an intent, a backstory), a behavior prompt (assertive wrong-number, voicemail emulation, polite happy-path booker, AI-skeptical objector), and a set of yes/no evaluation questions that the LLM judge will ask after each call. The personas dial the real production-shaped voice agent. They get answered. The call records, transcripts, and evaluations all flow back into a comparison dashboard.
The crucial discipline: every run compares two agents in parallel — a baseline (your current production) and a candidate (the change you are proposing). The eval reports per-question pass rates side-by-side, end-to-end latency bucketed at thresholds the team picks (a common split is sub-1.2s, sub-2s, sub-3.5s, slower), per-component latency for ASR / LLM / TTS, and behavioral metrics like agent disappeared, defined as "user spoke, then user spoke again, with no agent in between." Agent-disappeared is a zero-tolerance metric. Latency regressions are obvious. Behavioral regressions show up as a single question dropping from 100% pass to the low nineties, with the failing call IDs linked so a developer can play them back.
This is where prompt regressions get caught — the kind that unit tests cannot see. Someone tweaks one tool description to handle a new edge case, the change subtly weakens its differentiation from an adjacent tool, and suddenly an evaluator question that used to pass 100% of the time drops to 87%. The diff looks innocuous in PR review. Synthetic-call testing is what flags it.
Most teams running this at scale do not run it in CI. The reason is operational: a meaningful run is hundreds of calls against live LLM and TTS endpoints, costing real money and minutes. It is triggered by the AI engineer when they think the configuration is stable enough to advance. The CI tests cover code-path coverage; synthetic-call testing covers behavior coverage. Both are necessary. Neither replaces the other.
Warm transfer is a parallel-agent dance
The most elegant pattern in production voice-AI is the warm transfer.
When the main agent decides a transfer is warranted — the caller asked for a human, or the agent hit a path it cannot handle — it does not simply hang up and dial. It does two things in parallel:
- The main agent keeps chatting with the lead, holding their attention.
- A second transfer agent — its own configuration, its own model selection, its own prompt — initiates an outbound call to a destination number provided by the customer. That destination may be a human, a voicemail box, or an IVR maze with its own prompts and key-presses.
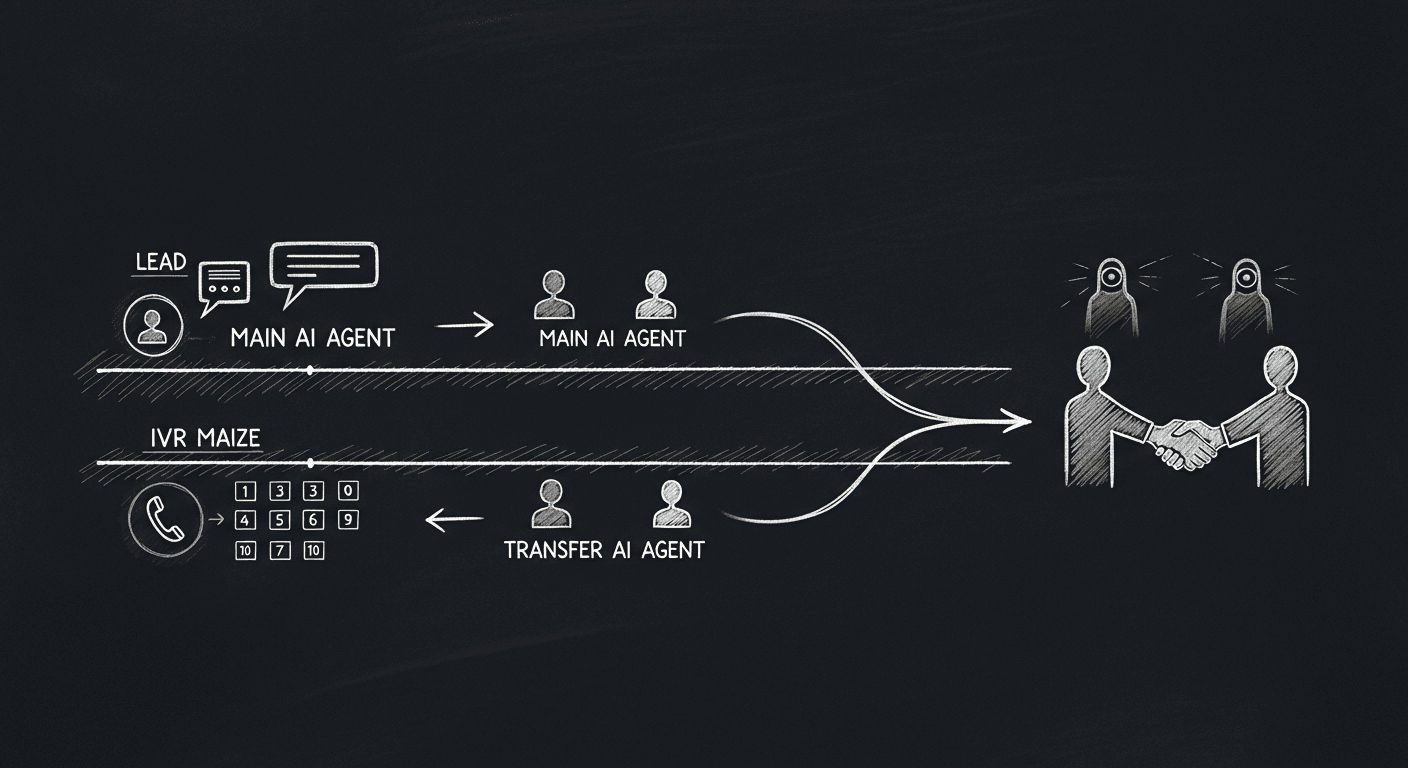
The parallel-agent dance. Two AI agents working in concert so the human handoff is seamless.
The transfer agent's only job is to traverse whatever stands between it and a real human. It listens, parses, key-presses, and signals success or failure back to the orchestrator. When success arrives, the orchestrator notifies the main agent, both AI agents say polite goodbyes within milliseconds of each other, and the human-to-human connection is left intact.
The reason this works is that both agents are agents. The transfer agent goes through its own synthetic-call testing — with personas mimicking IVR menus, direct human pickups, and voicemail boxes — before it is wired into any main-agent flow. When the main agent runs its tests, it mocks the transfer side with a trivial stub that picks up, waits a moment, and hangs up, so the transfer agent's behavior does not contaminate the main agent's metrics. Each piece is tested in isolation; integration testing happens at the orchestrator boundary.
Per-component latency is the only latency metric that matters
End-to-end latency — the time from "user stops talking" to "agent starts speaking" — is the metric that determines whether your agent feels alive or feels broken. Roughly: under a second is excellent, sub-1.5 is good, past two-and-change you can feel the seam, past three or four you start losing calls. The exact thresholds depend on the vertical and the kind of caller; the shape is the same everywhere.
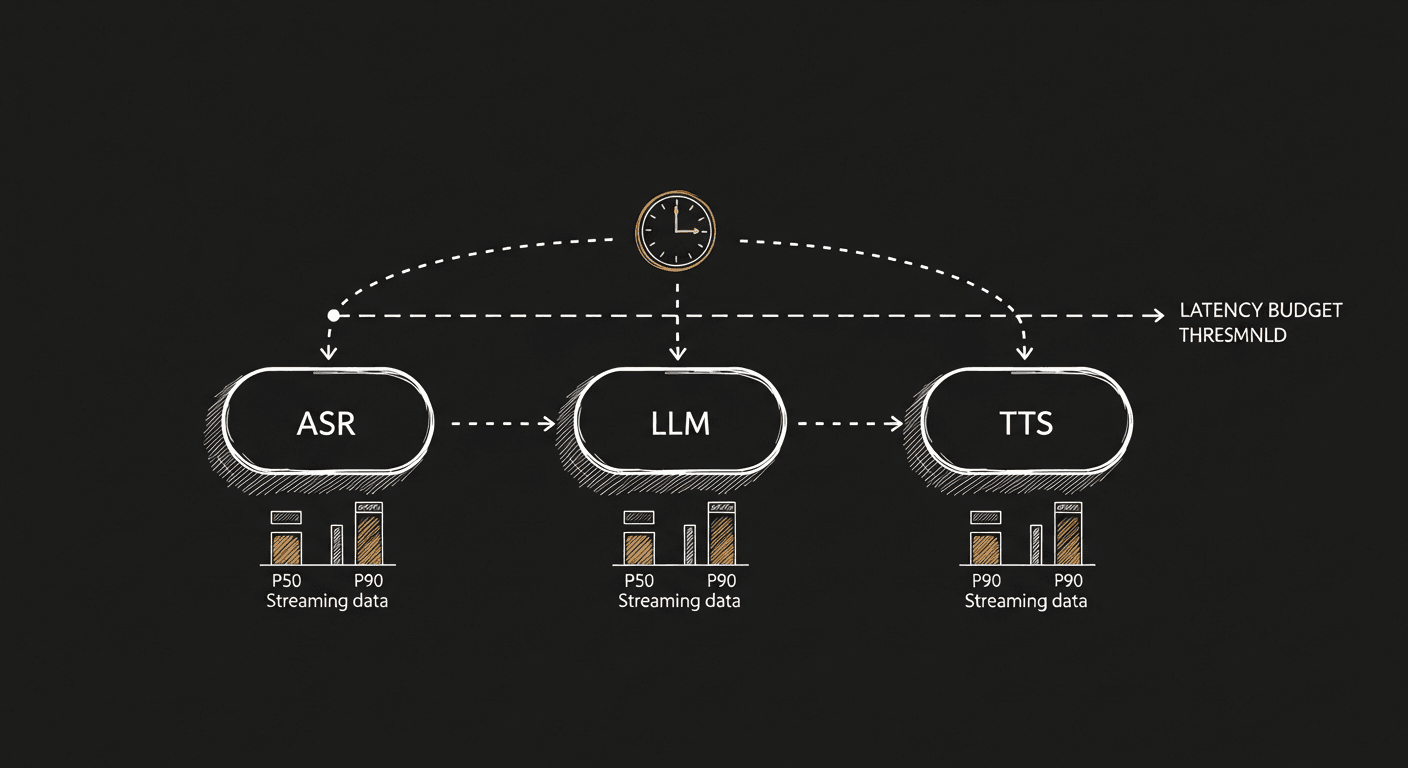
Three components, three latency budgets. The total has to fit under the line.
But end-to-end latency is useless for diagnosis. The teams that monitor voice agents seriously decompose it into three components and trace each independently: ASR (how long until we have a stable transcript), LLM (how long until we have the first token, then until we have a streamable response), and TTS (how long until we have the first audio byte). All three are streaming. All three are observable separately. Whatever distributed-tracing system you use should capture them as nested spans on every turn, with P50 and P90 alerts wired to whatever pages on-call.
The non-obvious failure modes live inside the components. Glitch detection is the canonical example: when the TTS provider does not feed the orchestrator audio bytes fast enough, the user hears silence gaps inside the agent's response. It does not show up in end-to-end latency. It does not show up in any aggregate metric unless you specifically built one. Mature teams run two parallel glitch detectors — one in the orchestrator (underrun detection in real time) and one as a post-call audio validator (silence-gap detection in recorded audio) — and aggregate both with per-call and rollup metrics. Alerts fire when the glitch rate crosses a threshold per campaign.
This level of observability is not optional in production voice-AI. It is the entire reason the system stays trustworthy.
A/B testing catches what humans cannot hear
This has now happened enough times across enough providers that it deserves a name.
A TTS provider — whichever one your team uses — updates their voice model. The agent sounds, to every human in the room, exactly the same. Maybe a tiny tonal shift at the end of certain sentences, but nothing you would call a difference. The team rolls the new voice into production at a small traffic slice (somewhere between 1% and 10%, depending on the team's tolerance for risk). Within a day or two, the conversion rate on that slice has dropped measurably. Within a week, the team is in a back-and-forth with the provider, A/B-testing parameter tunings until the regression closes.
The lesson is that voice quality is not perceptually evaluable by humans at the resolution that matters. It is statistically evaluable by population behavior. Real users on real calls vote with their conversions, their hang-up rates, their willingness to disclose personal information, their willingness to be transferred. The only way to know whether a model change, a voice change, or a prompt change is helping or hurting is to run it against a slice of production traffic and measure the metrics you actually care about.
The tooling for this is mature. Any modern feature-flag-with-stats platform will run the experiment; any warehouse-frontend handles the historical traffic analysis. The hard work is not the tooling. The hard work is defining the metrics — did the lead book, did they consent to a transfer, did they disclose required information — and committing to make decisions based on them rather than on what the team thinks sounds better.
Per-node model routing is the cost-and-latency lever
Once you have the graph and the decision/response separation, you get a powerful lever for cost and latency: per-node model selection.
A simple response node — "Great, what time works for you?" — does not need a flagship reasoning model. A static node — "Thank you for your time, we will mark this number as do-not-contact" — does not even need an LLM at all and can be hardcoded. A decision node that has to disambiguate between five tools with subtle overlap, or a node that needs to extract structured data from a free-form user response, does need the best model you can afford on the latency budget.
The pattern in production: each agent has a default model group (typically a flagship reasoning model) routed through a load-balancing proxy across multiple LLM provider endpoints, with health checks and automatic failover. Dev environments deliberately use slower or cheaper endpoints; production routes to the lowest-latency available endpoint that is not rate-limited. Per-node overrides drop down to faster, cheaper models — small open-weights, mini-tier hosted models — for response generation in simple nodes. The cost difference across hundreds of thousands of calls is large enough to fund a small team.
A specific failure mode to watch for: some models will emit tool calls as content rather than structured calls — printing the function name and arguments into the response stream as plain text. Mature orchestrators parse the streaming response, detect the give-away prefix deterministically, halt the stream, and rewrite the output as a real tool call before the TTS ever sees it. Captured unit tests cover the parser. Without this guard, the user occasionally hears the agent literally read a function signature aloud.
How evals work in an AI call center
Architecture is half of it. The other half is the evaluation discipline that surrounds the architecture — what an AI call center actually measures, where regressions get caught before customers do, and which gaps in the default tooling a mature team fills in itself. The list below is what comprehensive evaluation looks like in a voice-AI deployment that has matured past "the demo works" into "the call center works." None of it ships by default with any framework, hosted or homegrown.
The eval loop. The agent is one node in a circulation that also includes the personas testing it, the judge grading the tests, the dashboard surfacing the grades, and the engineer closing the loop.
Calibrate the LLM-as-judge against ground truth on a recurring schedule. When an LLM-as-judge question drops from 100% pass to the low nineties, three things could explain it: the agent regressed, the question is ambiguous, or the judge is mis-prompted. Mature teams hand-grade failing calls to disambiguate after the fact. Almost nobody systematically calibrates the judge against a versioned, hand-graded ground-truth dataset on a recurring basis. The judge drifts as silently as the agent does, and the only fix is to treat the judge as code that ships with its own test suite.
Commit outcome metrics in the PRD, before the build starts. Most scoping docs lead with functional requirements — "agent confirms identity, captures intent, attempts booking" — and defer success metrics to "the production engagement." By the time the production engagement arrives, the agent is shipped and the metrics get reverse-engineered to fit what the agent already does well. A scheduling-recovery rate or a per-call conversion lift belongs in the PRD before line one of configuration is written. Without that, every later A/B test is measuring an arbitrary direction.
Slice every behavioral metric by detected speaker characteristics. Voice agents behave differently across accents, ages, English fluency, and regional dialects. A synthetic-call question with a 92% aggregate pass rate can hide 99% on one demographic and 78% on another. Engineer adversarial personas explicitly to probe demographic robustness, and slice the eval dashboard by speaker characteristics that the ASR can already detect. This is the easiest extension to ship and the one most teams have not.
Make safety triage a first-class graph branch. "The call is recorded, I am an AI" is well-covered as compliance. "The caller just said something that suggests a medical emergency" or "the caller has expressed self-harm intent" rarely is. Without an explicit triage subgraph, the agent pattern-matches a crisis into the closest available tool. Healthcare and adjacent verticals need a triage branch that fires regardless of which node the conversation is currently in, with an explicit handoff path to a human or to a crisis resource.
Instrument welfare counter-metrics alongside conversion. Booking rate is the easy metric. Whether the caller felt respected, whether they regretted the interaction, whether they would consent to a future call — these are harder, slower, and rarely instrumented. An agent that pushes harder will move short-term metrics while burning longer-term trust. Repeat-call rate, complaint rate, and explicit revoke-consent rate are the counter-metrics that should sit on every A/B dashboard next to conversion.
Bring response-text quality into CI. Captured state tests verify which tool fired and which disposition was set. They do not verify that the response was natural, on-brand, or non-confusing. Response-text quality currently lives only inside synthetic-call runs, which are not in CI. The fix is an LLM-judged response-quality pass that runs per-PR on a small sample of cached node responses — cheap enough to run on every change, sensitive enough to catch a stilted prompt tweak before it ships.
Track cost-per-call as a regression metric. Latency budgets are sacred. Token budgets are not. A prompt change that grows one node's prompt by 30%, multiplied across millions of calls, is a meaningful margin hit — but most teams only notice when the monthly LLM invoice lands. Per-PR cost-delta tracking is a cheap addition: estimate tokens per turn on a representative call sample, compute the per-million-call delta, surface it next to the latency diff. The absence of this shows up as slow drift in unit economics that gets blamed on traffic mix.
Decouple persona authoring from agent authoring. The AI engineer writes the agent, the synthetic personas that test it, and the eval questions that grade the test calls. QA does a spot-check at the end. Whatever the developer could not see when writing the agent, they also could not see when writing the personas. A standing red-team — internal or contracted — authoring adversarial personas independently of the engineer who built the agent catches a class of failure modes the build pipeline cannot.
Test the main/transfer integration end-to-end, not just in production. Each agent gets its own synthetic-call run; the main-agent run mocks the transfer side with a stub. The actual parallel-agent choreography — both agents announcing exit, orchestrator handoff timing, races where the lead hangs up mid-transfer — only gets exercised in production. The seam between the two agents is the most interesting bug surface in the entire stack, and a small population of integrated synthetic calls (real main agent calling real transfer agent calling real stubbed-human endpoint) is enough to surface most of the failures before they reach a customer.
None of this is an argument against the architecture; the architecture is correct. It is a description of what a voice-AI deployment looks like once it has matured past "the demo works" into "the call center works." The teams that extend the stack in these directions next are the ones whose voice agents will stop being merely impressive and start being institutional — the kind of system a regulated business can stake its reputation on.
Outside voice: the pattern travels
Everything above is shaped by the constraints of voice — real-time audio, sub-two-second latency, the ASR/LLM/TTS pipeline. But the architecture and the evaluation discipline that wraps it are not voice-specific. The same shape shows up cleanly in any domain-specific AI agent: a clinical decision support tool, a golf caddie like MetaCaddie, a continuous care monitor like MetaVigil, a coding agent. The pipeline pieces change. The discipline does not.
The graph. A golf caddie has nodes for lie assessment, club selection, wind and distance compensation, hazard avoidance, and final recommendation. A care monitor has nodes for baseline modeling, anomaly detection, escalation tiering, alert routing. The graph shape changes by domain; the property that every conversation branch is an addressable, testable, observable thing does not. Once you have it, adding a new behavior is two minutes of work instead of two days.
Decision/response separation. A caddie picks an advice type — strategic, tactical, reassuring — and then generates the phrasing. A care monitor picks an alert severity and then generates the message and the routing. Splitting the routing decision from the output generation buys the same hallucination, latency, and cost wins it buys in voice. The wins are larger in any high-stakes domain where the which matters more than the how.
Synthetic users. Voice teams build LLM-driven caller personas. Golf teams build LLM-driven golfer personas — handicap range, course familiarity, stress level, willingness to deviate from the AI's recommendation. Care teams build LLM-driven recipient personas — baseline behavioral patterns, comorbidities, household composition. The discipline is the same: hundreds of synthetic runs against a candidate change, baseline vs candidate, an LLM judge grading yes/no behavioral questions about each session.
Calibrate the judge. The LLM-as-judge problem is universal. Whatever your domain, the judge has to be checked against expert ground truth on a recurring schedule, or it drifts as silently as the agent does. The expert in golf is a tour caddie. The expert in care monitoring is a geriatric specialist or a licensed nurse. The discipline is the same.
Per-component tracing. Voice decomposes into ASR / LLM / TTS. Other domains decompose differently — sensor ingestion / reasoning / presentation in continuous monitoring; perception / decision / output in caddie tools; retrieval / reasoning / formatting in coding agents — but the principle that end-to-end latency is useless for diagnosis applies everywhere. Trace each component independently or accept that you cannot fix what you cannot see.
A/B testing for subtle quality. Voice has the TTS-update-that-tanks-conversion story. Caddies have the recommendation-phrasing-that-changes-shot-selection story. Care monitors have the alert-threshold-that-changes-family-trust story. The same lesson lands every time: human perception is not predictive of population behavior at the resolution that matters. Slice production traffic, measure the metrics you actually care about, decide from the data.
Welfare counter-metrics. Conversion is the easy metric in any domain. The harder metrics — did the user enjoy the round, did the family feel respected, did the patient feel watched and not surveilled — sit on every dashboard alongside conversion or they get optimized away.
If you are building a domain-specific AI agent in 2026, the question is not whether you need this stack. It is whether you build it deliberately or rediscover it the hard way.
What most voice-AI teams are still missing
If you take everything above and look at the gap between it and where most voice-AI projects sit today, three things stand out.
Decision/response separation. Most agents are still a single prompt doing both jobs. The latency, hallucination, and model-cost wins from splitting them are too large to ignore once you have seen them.
Edge cases as first-class graph citizens. Wrong number, voicemail, agent-suspected-AI, opt-out, mid-call hang-up, multi-language switches — these are not exceptions to handle inside the prompt. They are nodes with tools and dispositions. Treat them that way and they stop hallucinating.
Voice quality as a measurable variable. If you cannot tell the difference between two voices by ear, your conversion metrics still can. Build the population-level evaluation infrastructure or accept that you are making model-selection decisions blind.
The shape is here. The teams that have lived through enough production cycles have built into it. The convergence is not because everyone copied each other. It is because the constraints — sub-two-second latency, real compliance, real money, real users hanging up — push every serious team toward the same architecture.
Voice-AI is no longer interesting because the demo is impressive. It is interesting because the production stack now has a known shape, and the teams building inside that shape can iterate on real problems instead of fighting their tools.