Articles from 2024
17 articles published in 2024.

Every Failed AI Product Has the Same Root Cause
The same failure pattern shows up everywhere: teams shipping fast and iterating on vibes instead of building systematic evaluation. Evals aren't a nice-to-have. They're the core competency of any serious AI product team.


The 6 Ways I've Watched GenAI Projects Fail (And How to Avoid Them)
GenAI projects in healthcare go sideways in predictable ways, sometimes with real patient consequences. Six failure modes that come up over and over again, and what to do instead.


When to Look Beyond Standard LLMs (And When to Stop Overthinking It)
Most teams should use a frontier API and move on. There are specific situations where alternative architectures matter: extreme latency, long-context scale, cost walls, privacy constraints. The decision framework.


When Recommendations Meet Language: The LLM-RecSys Convergence
Most AI stacks treat the recommendation engine and the language model as two separate systems that hand off to each other. A new class of hybrid models eliminates that seam. The implications for domain-specific AI are significant.

Trading Speed for Quality: A Practical Guide to Inference-Time Scaling
Inference-time scaling lets you tune the latency-quality tradeoff at runtime instead of at training time. When to use Best-of-N sampling, beam search, iterative refinement, or one-shot generation, with real examples from clinical AI.

Inside the Black Box: What Mechanistic Interpretability Means for Builders
Healthcare AI requires explainability. 'The model said so' is not a clinical rationale. Mechanistic interpretability is the research field trying to change that. What it offers practitioners today, where the gap is, and what to do in the meantime.

How to Actually Test If Your AI Will Say Something Dangerous
Most teams treat jailbreak testing as a vibe check. StrongREJECT achieves 0.90 Spearman correlation with human judgment. Automated safety evaluation is real, and there's no excuse not to build it into your pipeline.
The Attack Your LLM App Is Definitely Vulnerable To
Prompt injection is the #1 OWASP threat to LLM applications and most teams aren't taking it seriously. What the attack looks like, why it's hard to stop, and how to harden your system.


The Honest Guide to LLM Evals: What Actually Works
Most teams skip real evals and wonder why their AI products degrade in production. The framework that holds up: from 30-minute manual reviews to binary scoring to knowing when your eval suite is finally doing its job.

5 Reasons to Solve for Adoption Before Building Your Digital Health Tool
Clinicians love the idea but no one's buying. That gap is a pattern, and it almost never comes down to the technology. Five adoption problems to solve before you build the product.


Why Your LLM Evaluator Is Lying to You
LLM-as-judge evaluators feel like quality assurance but behave like rubber stamps. They fail hardest on the outputs that matter most: edge cases, safety-critical errors, domain-specific nuance. What to do instead.
Why I Stopped Using RAG for Coding Agents (And What I Do Instead)
The instinct when building a coding agent is 'I need RAG to handle large codebases.' The better instinct is giving the agent tools to explore code the way a senior engineer would: reading files, following imports, tracing execution.
React Tooling 2024: Stop Using the Wrong Shit
20+ React apps built this year. What works, what's a waste of time, and why you're probably overengineering.

The Neural Net Training Recipe That Actually Works
I spent months chasing architecture fixes when my real problem was bad debugging hygiene. The training recipe that works: start simple, visualize everything, tune last. The unglamorous discipline that separates working models from expensive experiments.
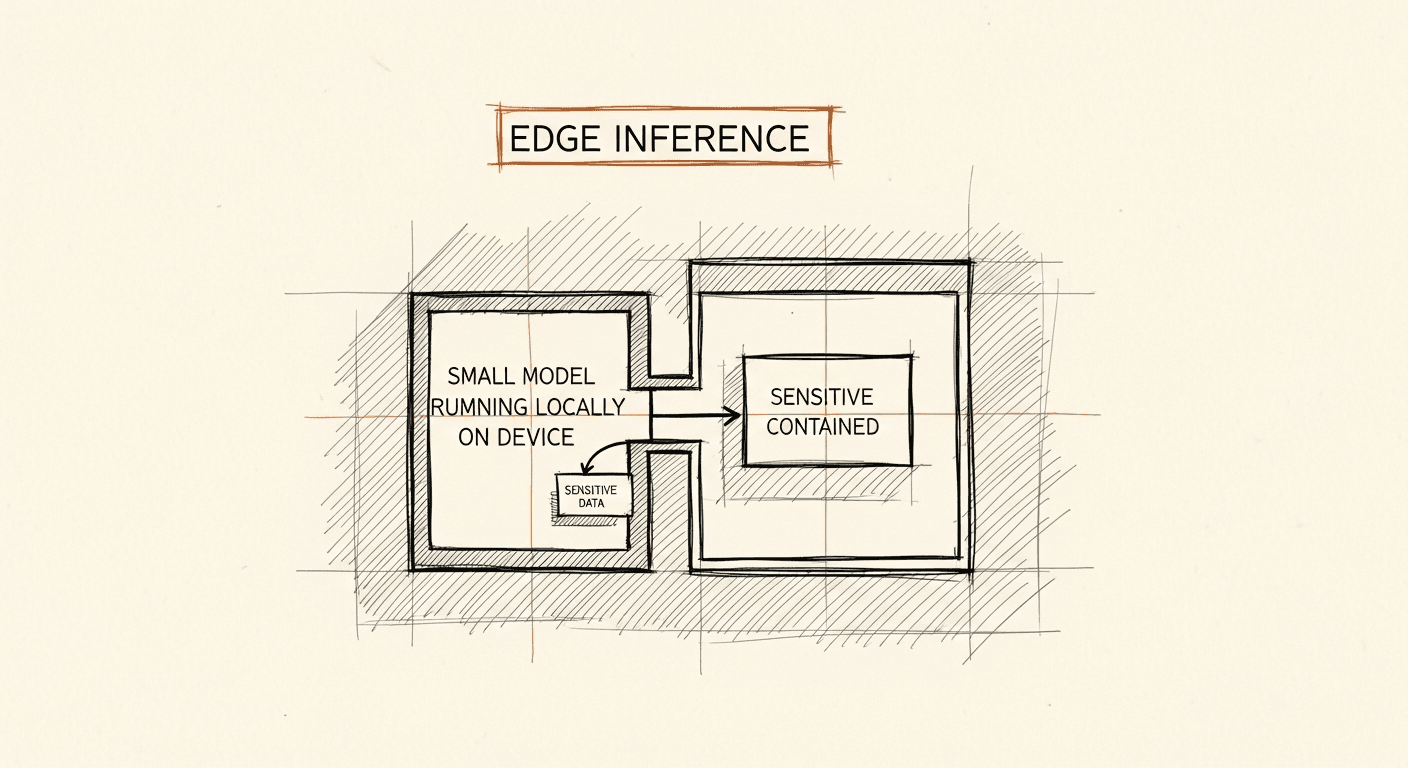

You Don't Need GPT-4 for That: Small Models and Edge Agents
Frontier models aren't required for agentic function calling. For healthcare AI, assuming they are can also be a compliance liability. When a fine-tuned 7B model is the right architecture, and when it isn't.
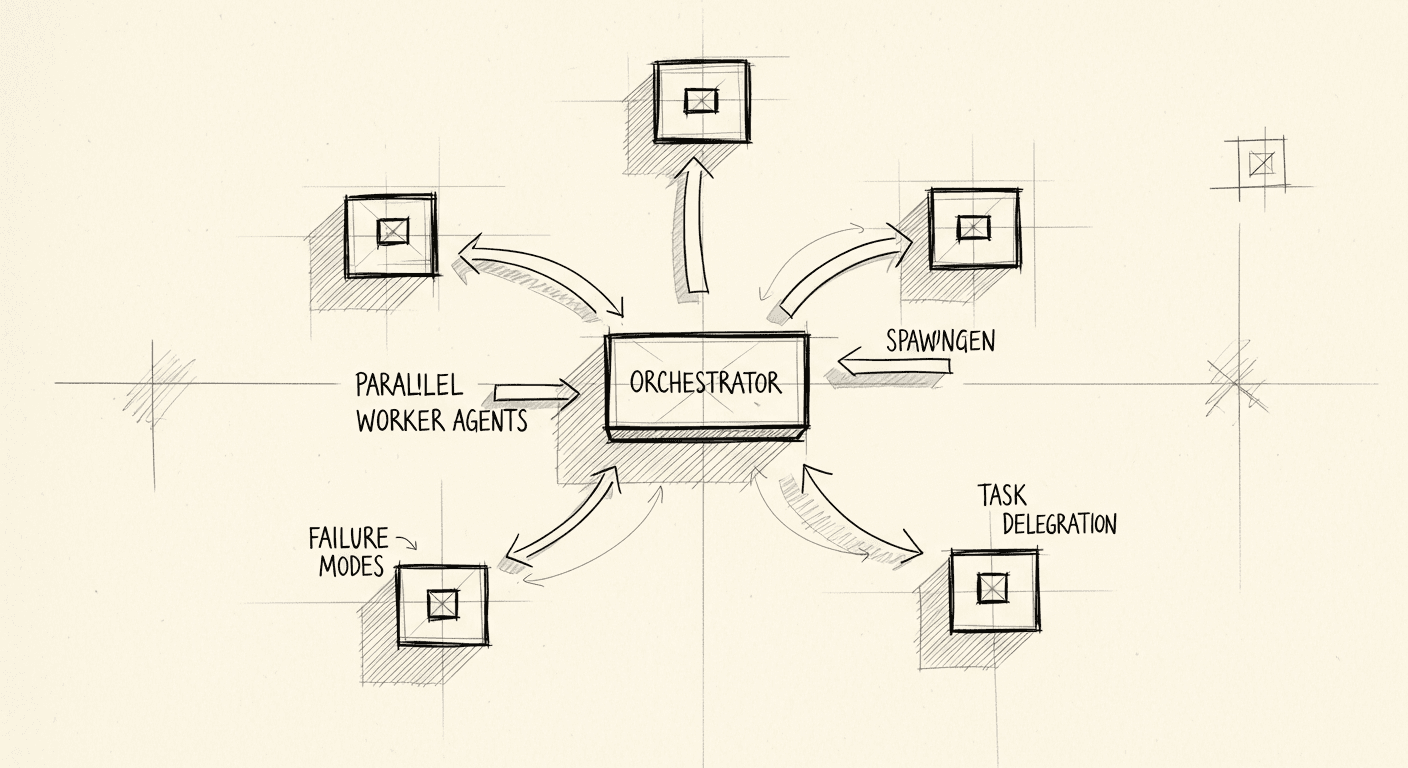
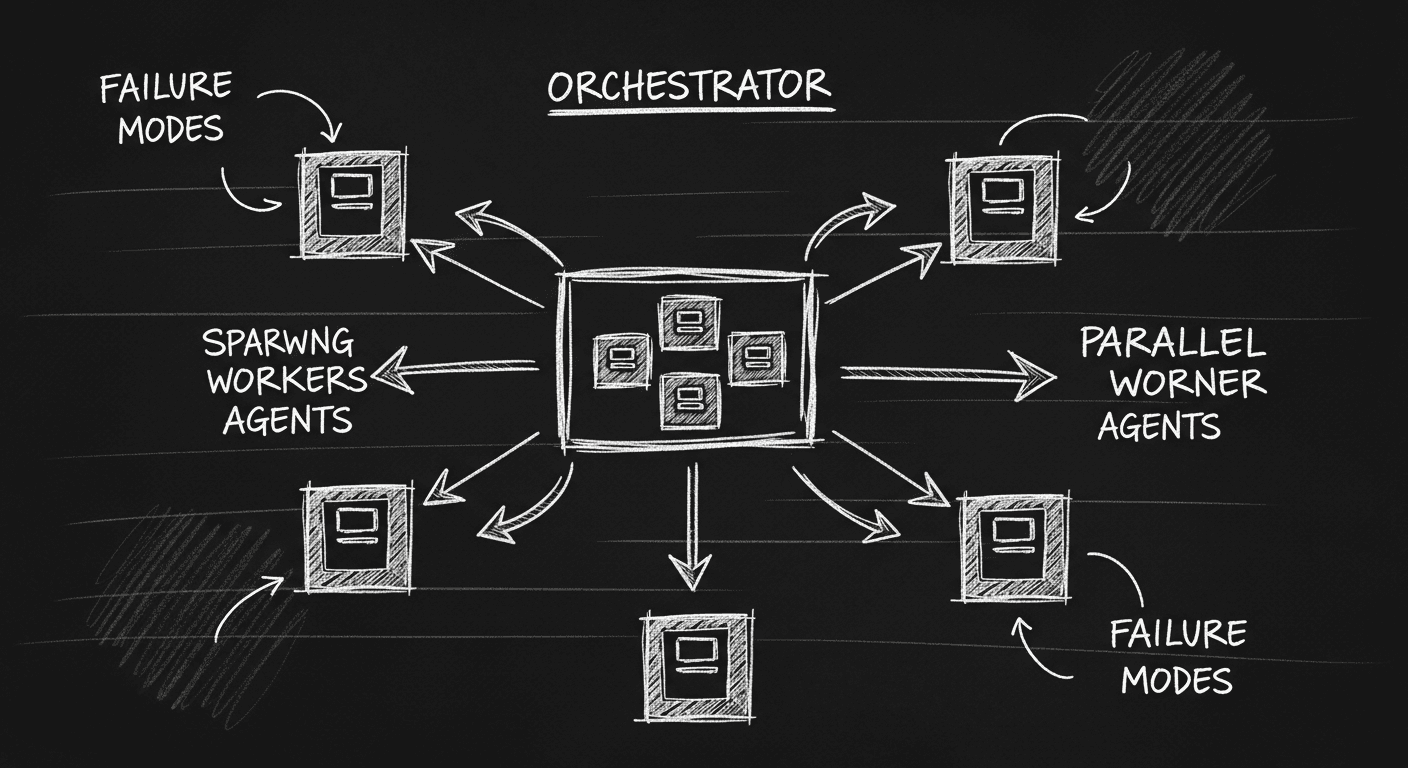
Multi-Agent Orchestration in Practice: What I Learned Building Parallel Agent Systems
The orchestrator/worker pattern is the key mental model for multi-agent systems. How to structure orchestrators, spawn and manage workers, aggregate results, and avoid the coordination failures that sink most implementations.
What It Actually Takes to Build a Real LLM Agent
Everyone's talking about agents. Few have shipped one that works in production. The failure modes, memory tradeoffs, and tool design decisions the architecture papers skip.