Engineering
59 articles in Engineering.
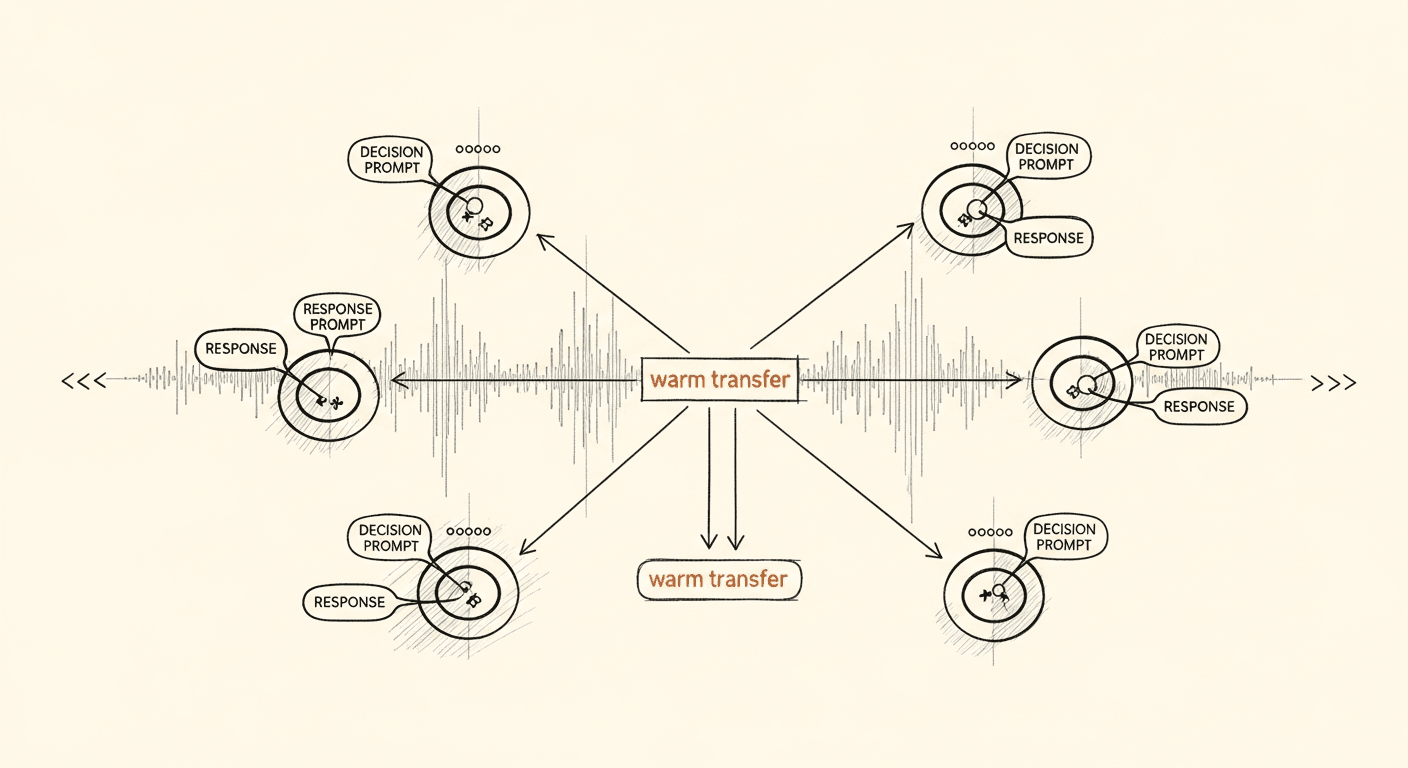
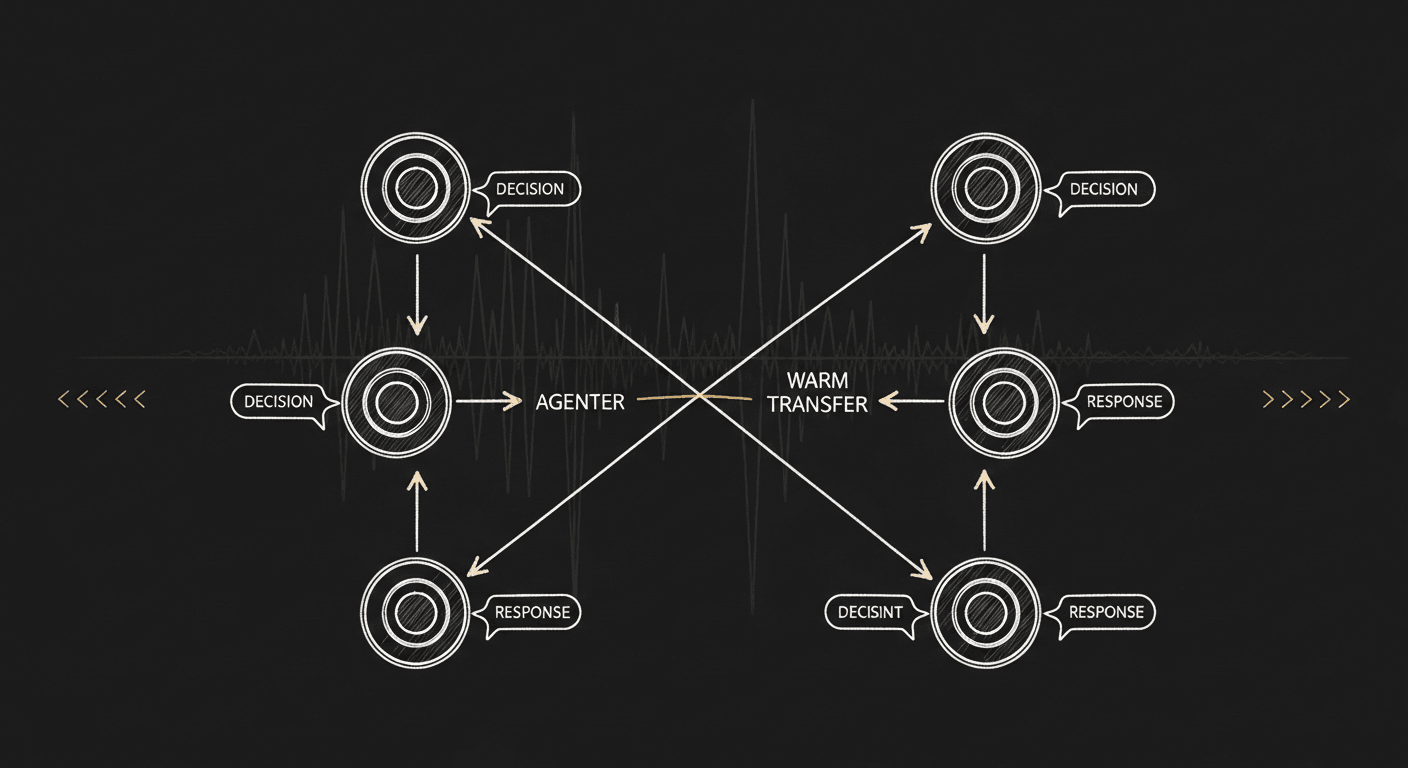
Inside a Production Voice Agent: How the Stack Actually Ships
Production voice-AI has converged on a pattern: graph-based conversations, separated decision and response prompts, synthetic-call regression testing, and per-component latency budgets. Why the stack looks the way it does — and what most teams are still missing.


Prompt Engineering Didn't Die. It Got Unrolled.
Everyone keeps announcing the death of prompt engineering. They are describing the symptom, not the shift. The loops you used to run by hand — refine, retry, verify, learn — moved out of your head and into infrastructure. Four of them, simultaneously.

The Two Rhythms of B2B Tech: What Palantir Gets Right That Most Companies Get Wrong
Palantir built a company on the idea that software alone isn't enough: you need engineers embedded with customers. That model has a name, a cost, and a hidden technical debt time bomb most B2B companies are quietly sitting on.

Penpal: Dispatch Tool Today, RPG Interface Tomorrow
I built a tool that turns GitHub issues into pull requests using a three-agent pipeline. That's the boring part. The interesting part is what happens when you stop thinking about AI agents as productivity tools and start thinking about them as a workforce, and build a world for them to live in.
Mirth Connect, what happened? Here's What Comes Next.
Mirth democratized healthcare integration. Then NextGen acquired it, and the world moved on. What the next generation of integration tooling looks like, and why the transition was inevitable.


Product Evals in Three Steps (That You'll Actually Do)
Most teams skip evals because the process feels overwhelming. The three steps that make eval-driven development achievable: label a small dataset, calibrate an LLM evaluator to human judgment, then iterate configs against the harness.
Table Stakes for Pragmatic Development Using LLMs
Updated for 2026: lessons from two years using Claude Code in production. Context engineering, real eval frameworks, model economics, and agent workflows. What works.


Staff Engineer Layoff Survival Guide: Lessons from 2008, 2020, 2023 — and Now
I've survived three tech recessions. Lost my job in one, held the axe in another. The AI boom changed the rules again. The updated playbook for 2026.


The Principal IC Playbook Nobody Shares With You
Reaching principal is the first rung of a new ladder, not the last rung of the old one. What nobody told me about the ownership-autonomy paradox, how leverage works at this level, and the charter model I wish I'd had from day one.

The ESM Mess: JavaScript's Module System Is Still Broken and Here's Why
ES Modules have been the supposed future of JavaScript for nine years. Only 9-27% of the ecosystem has adopted them. What's really going on, and how to survive until the ecosystem commits.


The Three Things Exceptional Engineering Leaders Do (And the One They Stop Doing)
Most engineering leaders excel at one of three pillars and quietly fail at the other two. The three are: providing direction, removing obstacles, foreseeing change. What it takes to build strength across all three.


The Open-Weight LLM Landscape in 2026: What Engineers Actually Need to Know
The open-weight ecosystem has matured faster than most engineers realize. MoE proliferation, hybrid attention, and extended context windows are changing what's deployable on-premise. That matters more than ever for healthcare AI.
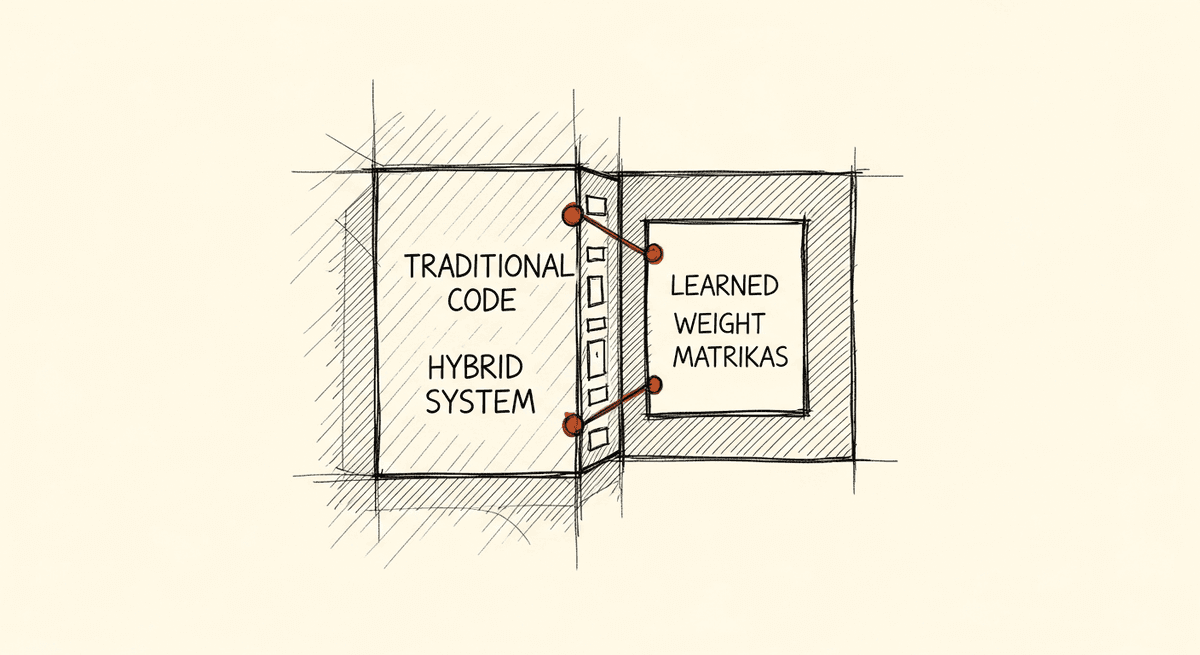
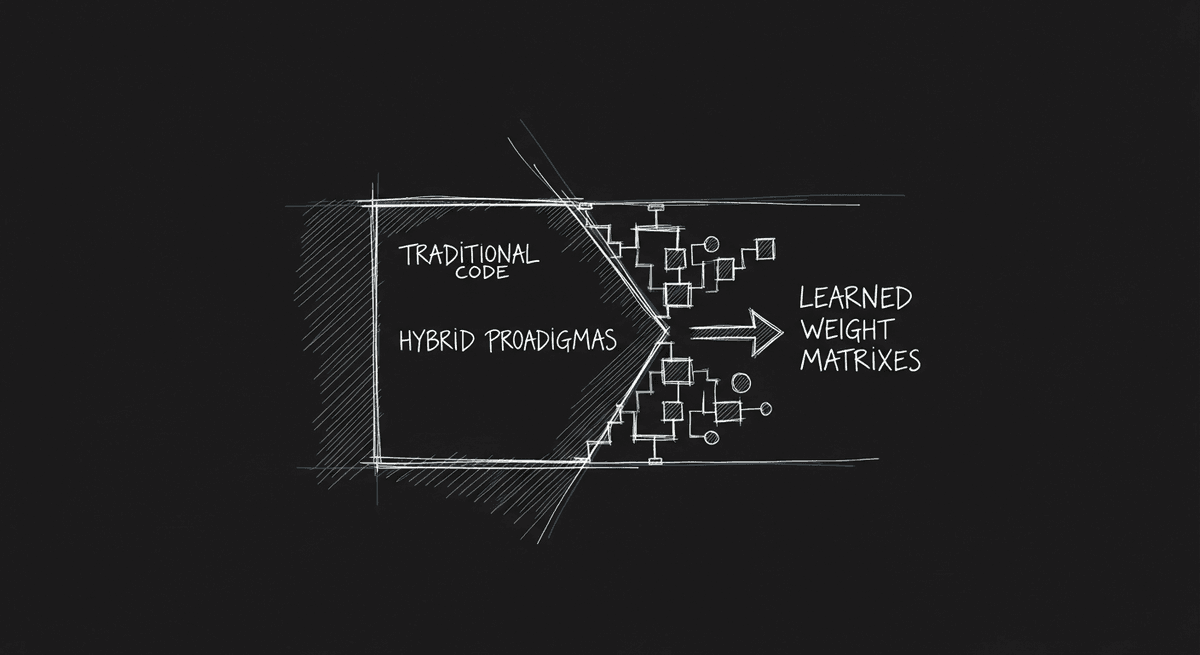
Software 2.0 Is Here and It Changed How I Think About Programming
In 2017, Andrej Karpathy argued that neural networks would replace explicit logic as the dominant programming paradigm. Nine years later, that prediction has fully landed. The implications for how we build software are bigger than most engineers want to acknowledge.
Three Ways to Know If Your Career Is Actually Growing
Normal career metrics: title, pay, team size. They tell you how you're doing relative to others. They don't tell you whether you're growing. Three metrics that do.


RAG Isn't Dead. You're Just Using It Wrong.
The 'RAG is dead' narrative is wrong, but it's wrong in an interesting way. What kills LLM context quality in production, and what to do about it.


Fine-Tuning a 70B Model on a Consumer GPU: The Q-LoRA Practical Guide
Q-LoRA + SFTTrainer + Flash Attention v2 means you can fine-tune a 70B parameter model on 24GB of VRAM. What that looks like end-to-end, what it costs in quality, and when to just use the API instead.
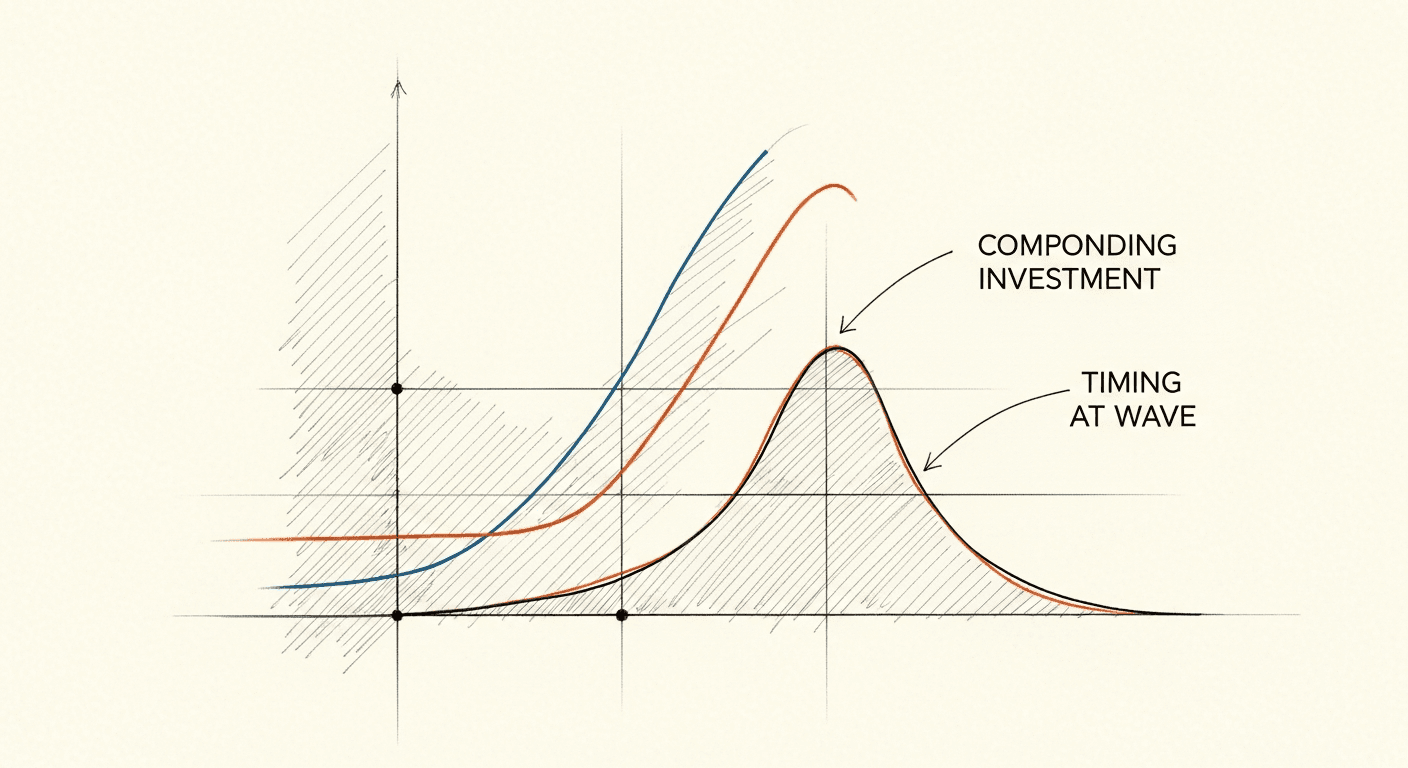
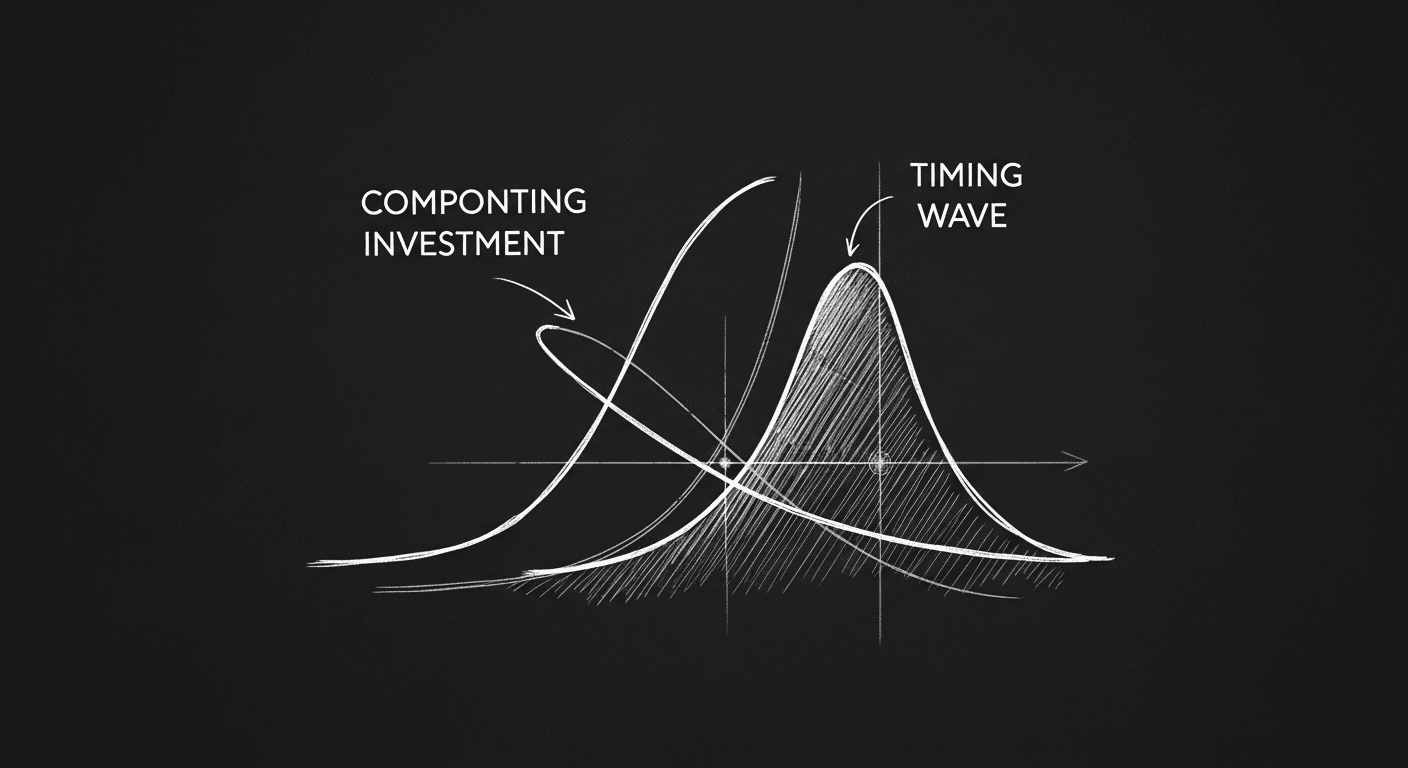
Time vs. Timing: The Career Framework I Wish I Had Earlier
I've made bets that paid off because of timing and bets that paid off because of compounding. Confusing the two is how careers stall.
The LLM Year in Review: What Actually Mattered in 2025 (And What Was Noise)
The prediction was: bigger models win. The reality was: DeepSeek R1 rewrote the rules in January and nothing was the same after that. What 2025 taught us about reasoning, inference-time compute, and the economics of intelligence.
From Contractor to Consultant: The Mindset Shift That Changes Your Income
Contractors sell time. Consultants sell results. That distinction is the whole game. How I changed my pricing, positioning, and client selection once it clicked.
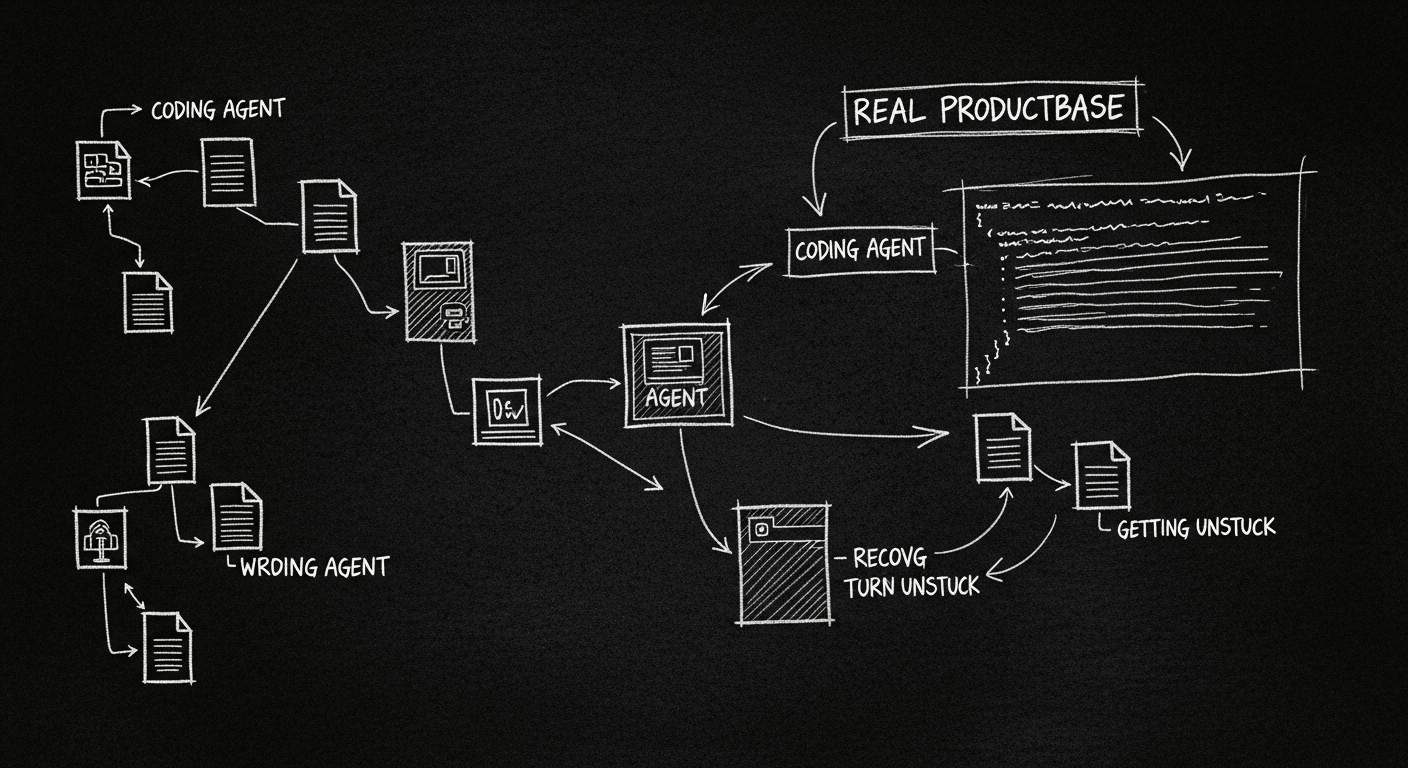
What the Teams Actually Shipping Coding Agents Have Figured Out
Coding agents are the most economically viable AI in production today. The patterns Devin, Cline, Amp, and others converged on, and what they mean for anyone building or using agents seriously.

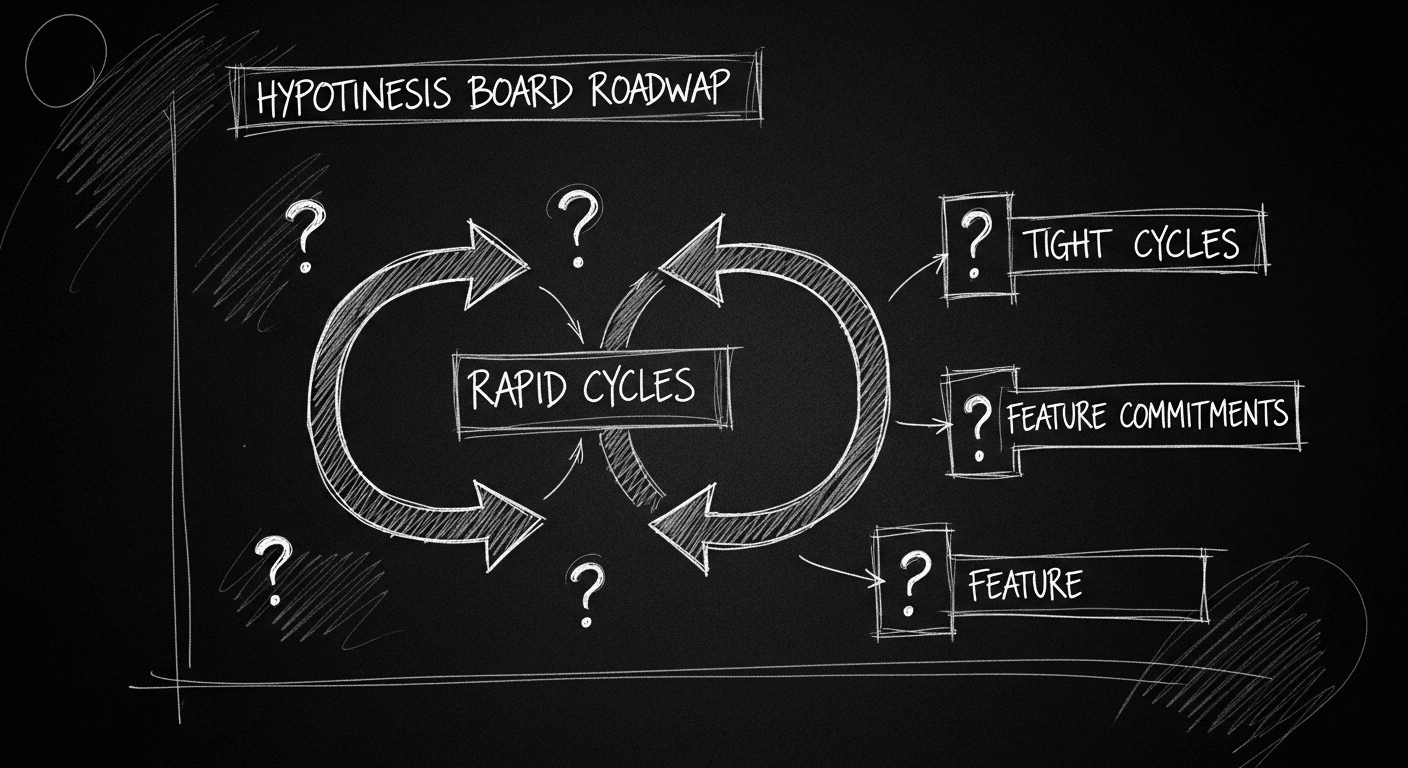
Stop Shipping Features: Why AI Products Need an Experiment Mindset
12 features shipped in a quarter. Zero meaningful metrics moved. AI products aren't software projects. The roadmap is a hypothesis board, not a delivery schedule, and treating it otherwise is expensive.
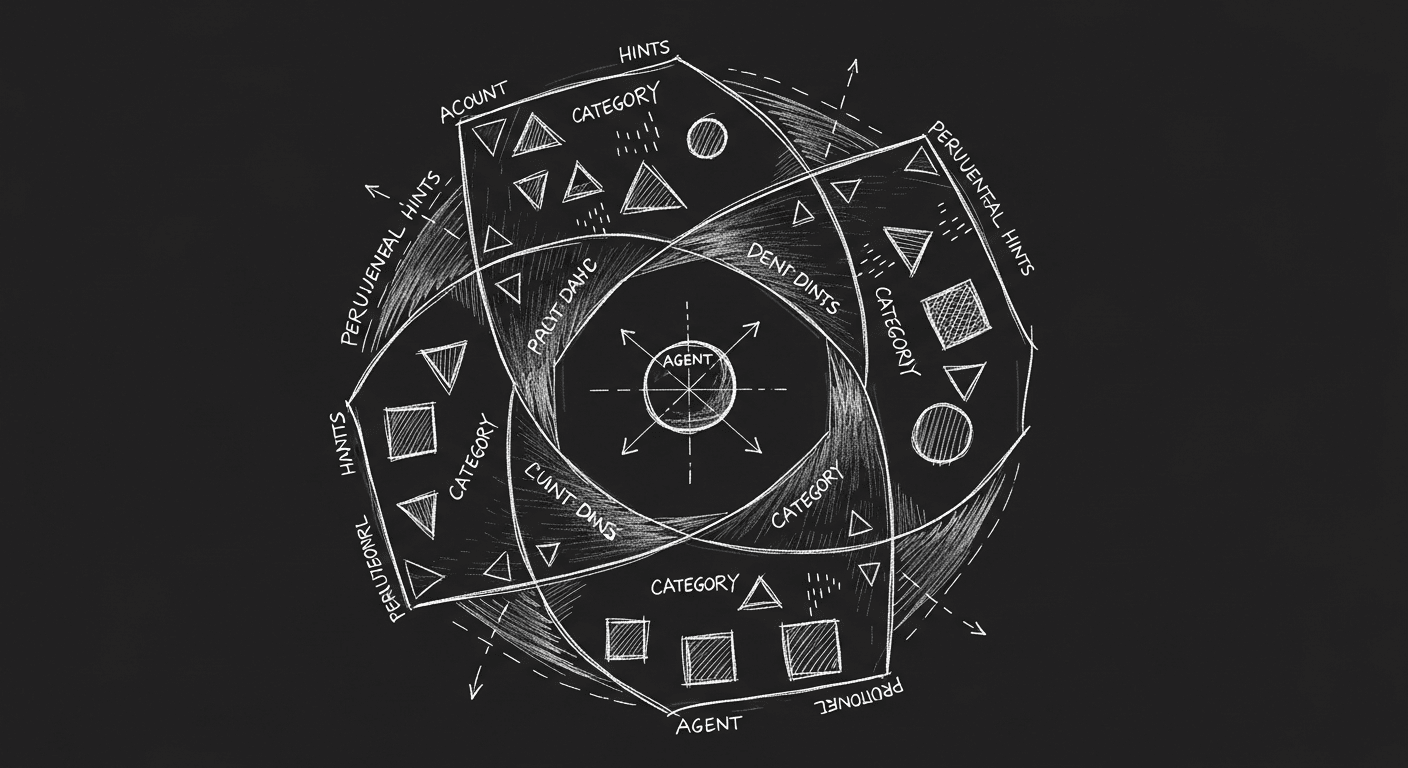
Beyond Chunks: Why Faceted Context Is the Future of RAG
Chunk-based RAG returns results. Faceted context gives agents peripheral vision: an understanding of the information landscape that lets them navigate rather than just consume. What that looks like in a domain where getting it wrong matters.

Context Engineering: The Skill That Replaced Prompt Engineering
Prompt engineering is a symptom, not a skill. The engineers shipping better agents aren't writing better instructions. They're designing better information spaces. Context engineering is the meta-skill no one teaches.


Every Service Is Going to Need an MCP Layer
REST APIs were designed for humans calling services through UIs. AI agents are not humans. What breaks when you expose your existing APIs to agents, and what the right architecture looks like.

When English Became a Programming Language
v0 just proved that English plus AI can replace traditional web development for most apps. That changes what it means to be a developer. An honest take on what shifts, what doesn't, and what to do about it.

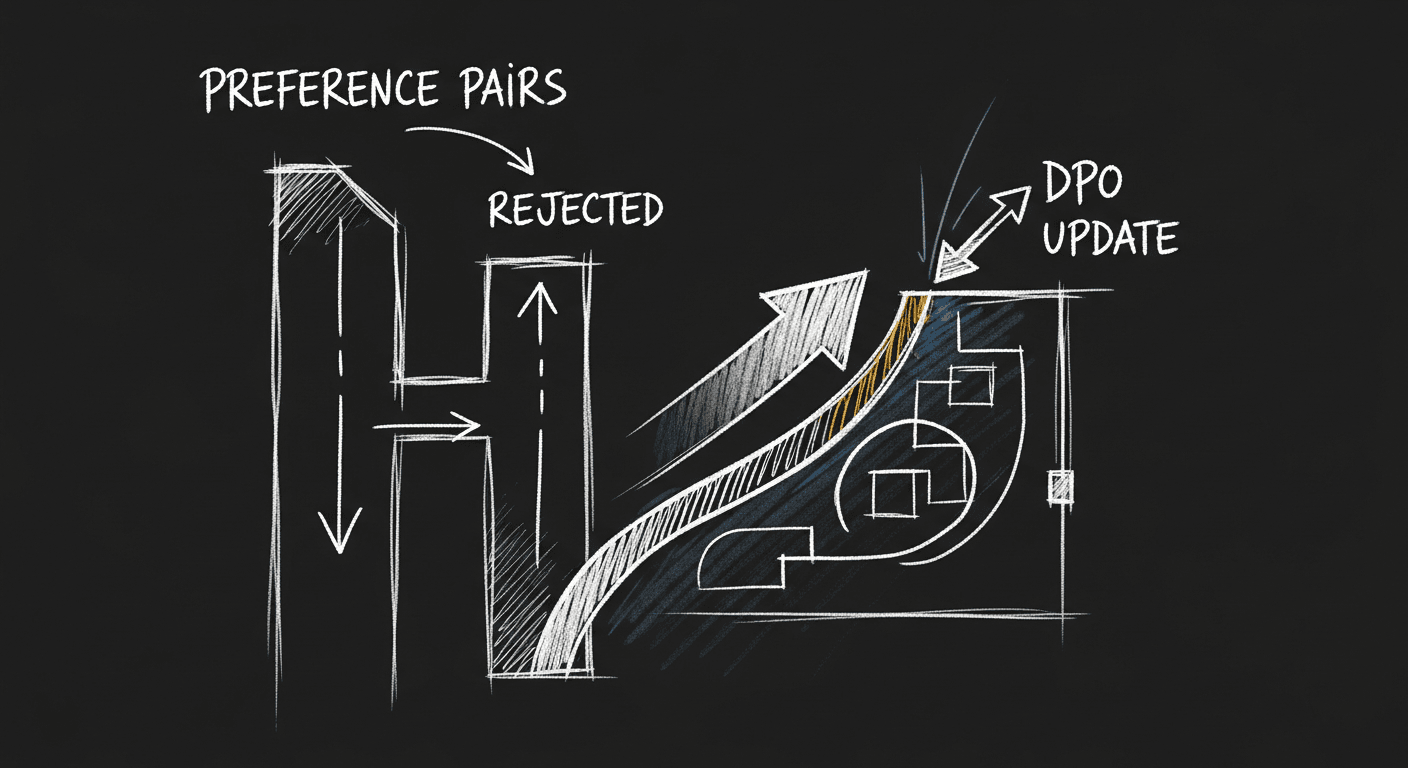
Fine-Tuning LLMs Without the RLHF Headache: The DPO Approach
RLHF is the right idea with the wrong implementation cost for most teams. DPO flips the math. How to align a healthcare AI model on clinician feedback without burning a month on reward model engineering.


Agency Beats Intelligence: How I Now Hire (And Evaluate Myself)
Raw intelligence is abundant and cheap. The engineers thriving in the AI era are the ones with agency: setting goals, acting under uncertainty, self-correcting. How I changed my interview process to find them.


You Are No Longer a Coder: The Shift from Execution to Direction
I stopped writing most of my own code. What changed, what I delegated to AI, what I found it can't do, and why the hardest part of the transition had nothing to do with technology.
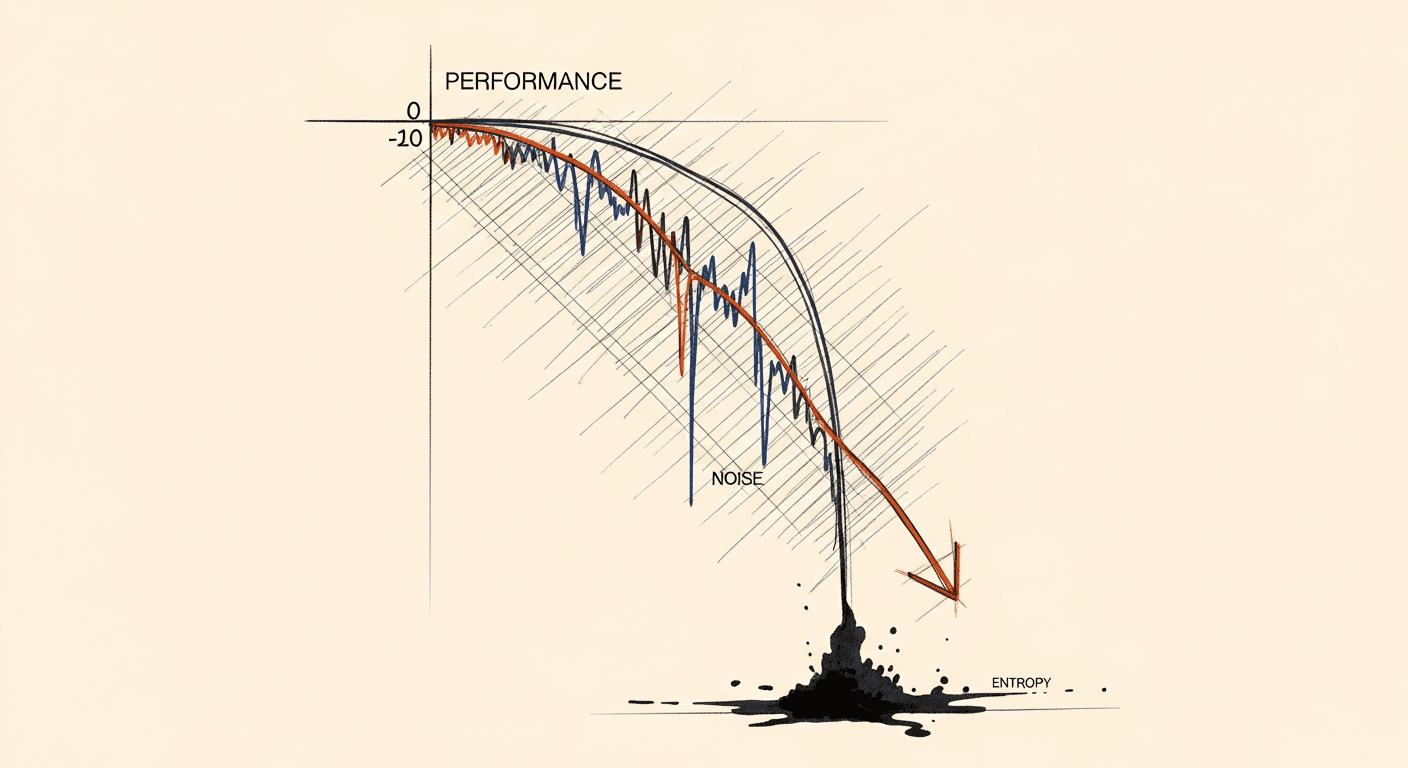
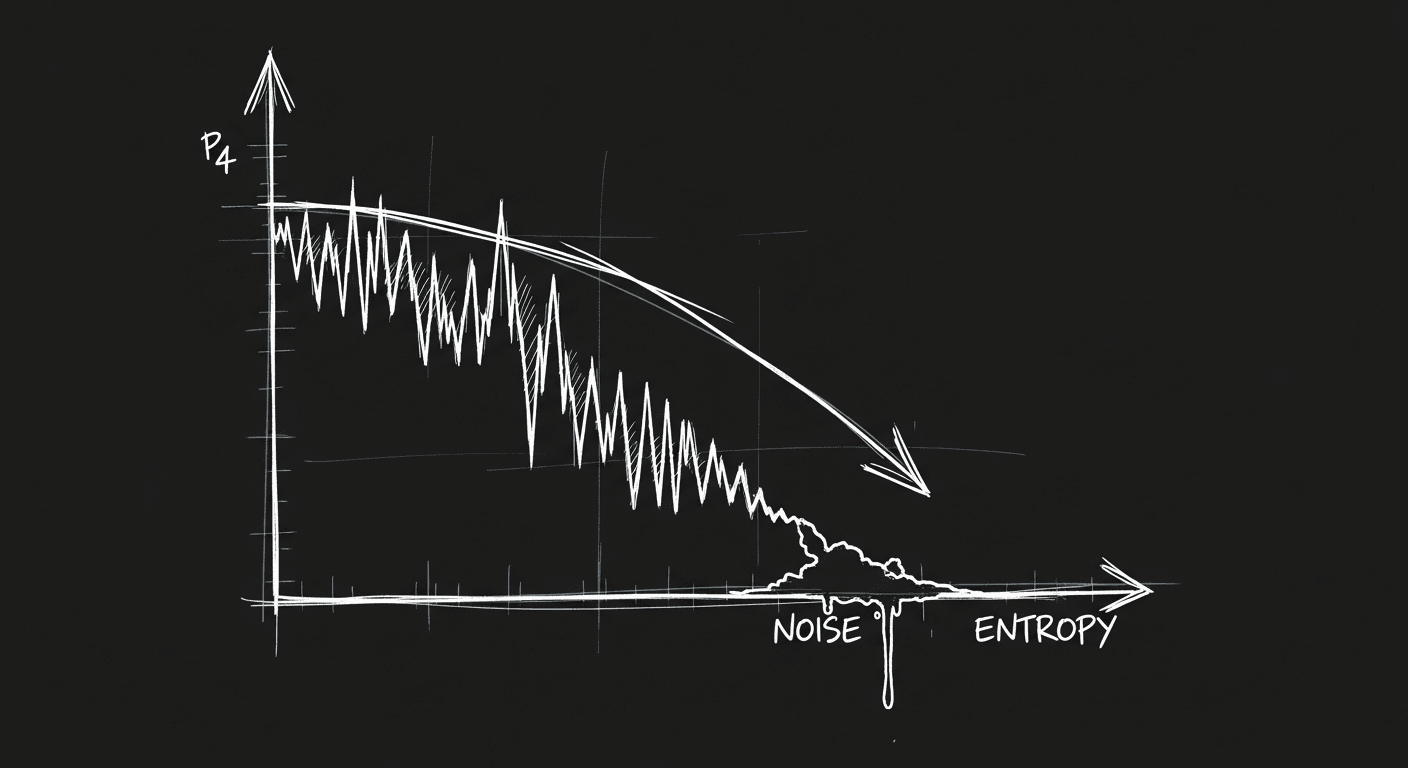
Context Rot: The Silent Performance Killer in Your LLM Application
Your LLM system works great in demos and degrades in production. The culprit is almost never the model. It's what you're feeding it. How to diagnose and fix context rot before it kills your product.
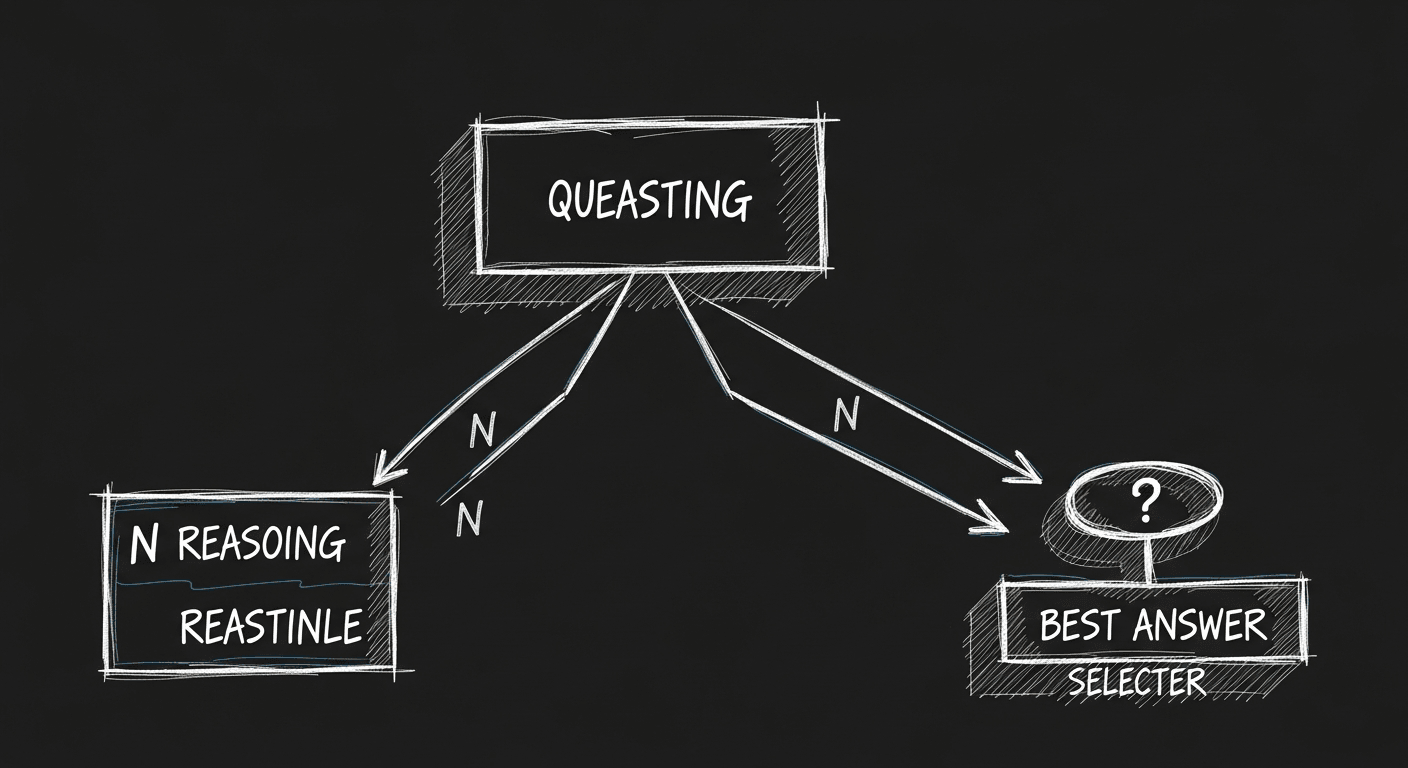
Why Your AI Gets Smarter When You Let It Think Longer
Test-time compute is the most underused lever in production AI right now. What chain-of-thought, best-of-N sampling, and process reward models mean for practitioners, and when to use them instead of grabbing a bigger model.

The Async-First Engineering Team: What Actually Works (And What Doesn't)
I went async-first with my remote engineering team. Productivity went up. Culture took a hit. What changed, what broke, and the specific practices that made it worth it.


What the AI Tool Ecosystem Is Actually Telling You
Tool selection in healthcare AI is a compliance problem, not a productivity one. Most AI tools that sounded great in 2023 are dead or deprecated. The framework I use for betting on the right ones.
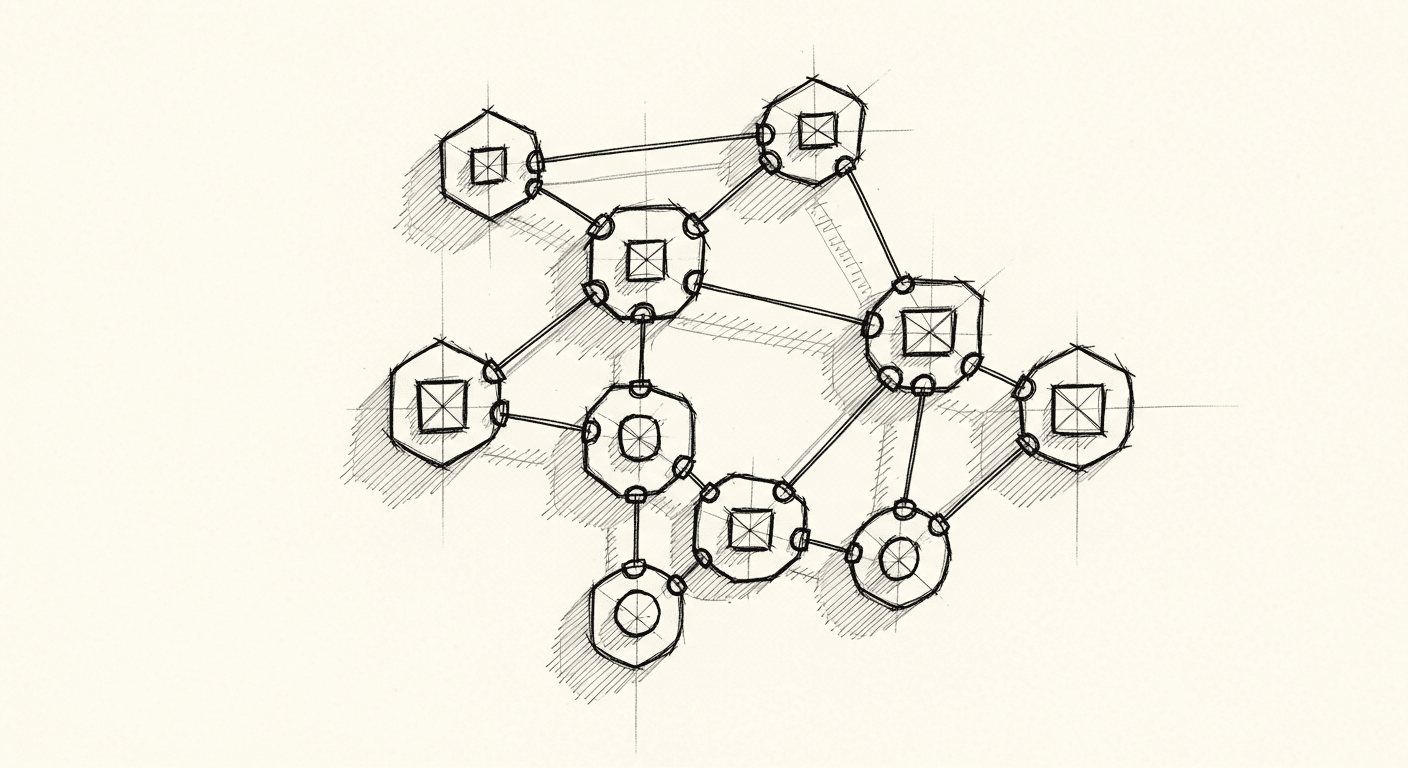
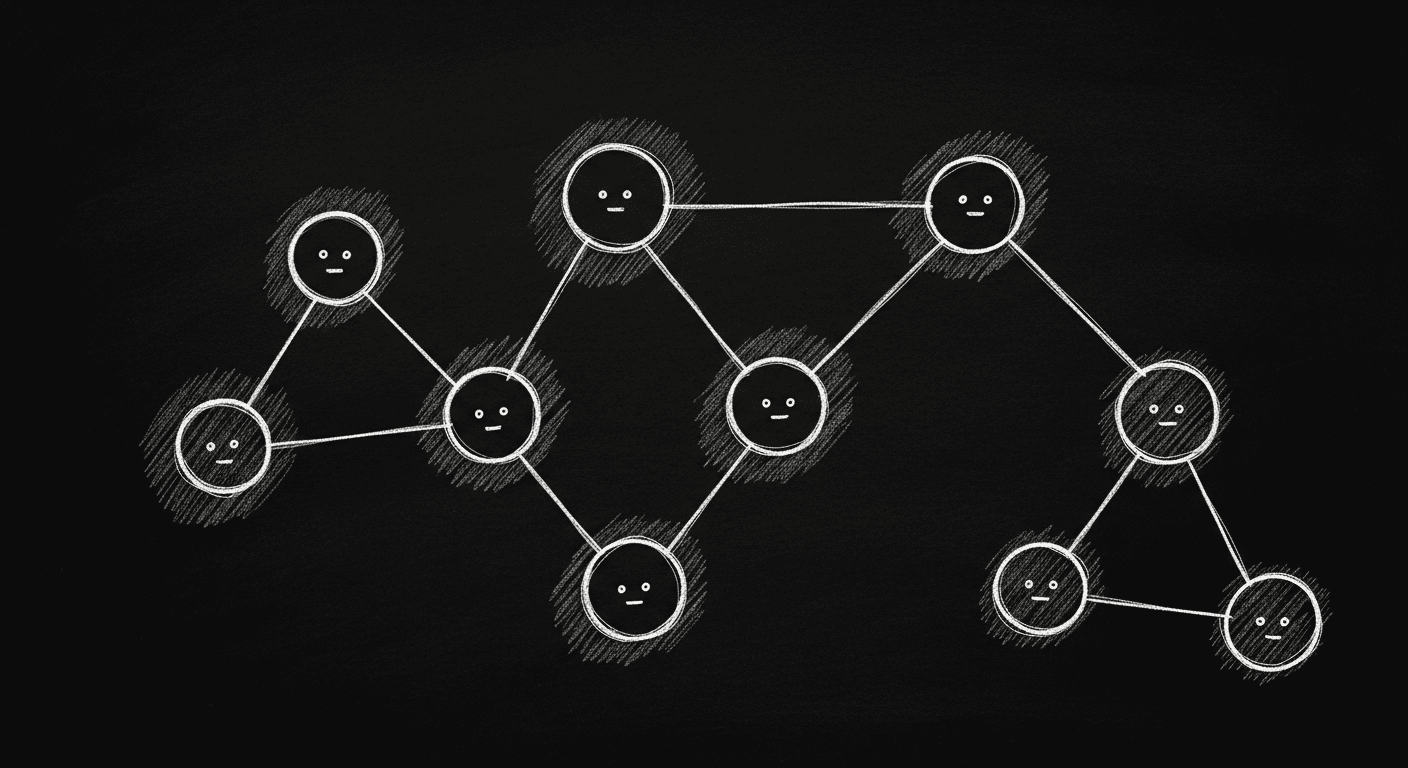
What Autonomous Vehicles Taught Me About Multi-Agent AI Design
BAIR researchers discovered that just 5% autonomous vehicle penetration can smooth all highway traffic, with no central coordination. That finding reshapes how I think about building multi-agent AI systems.
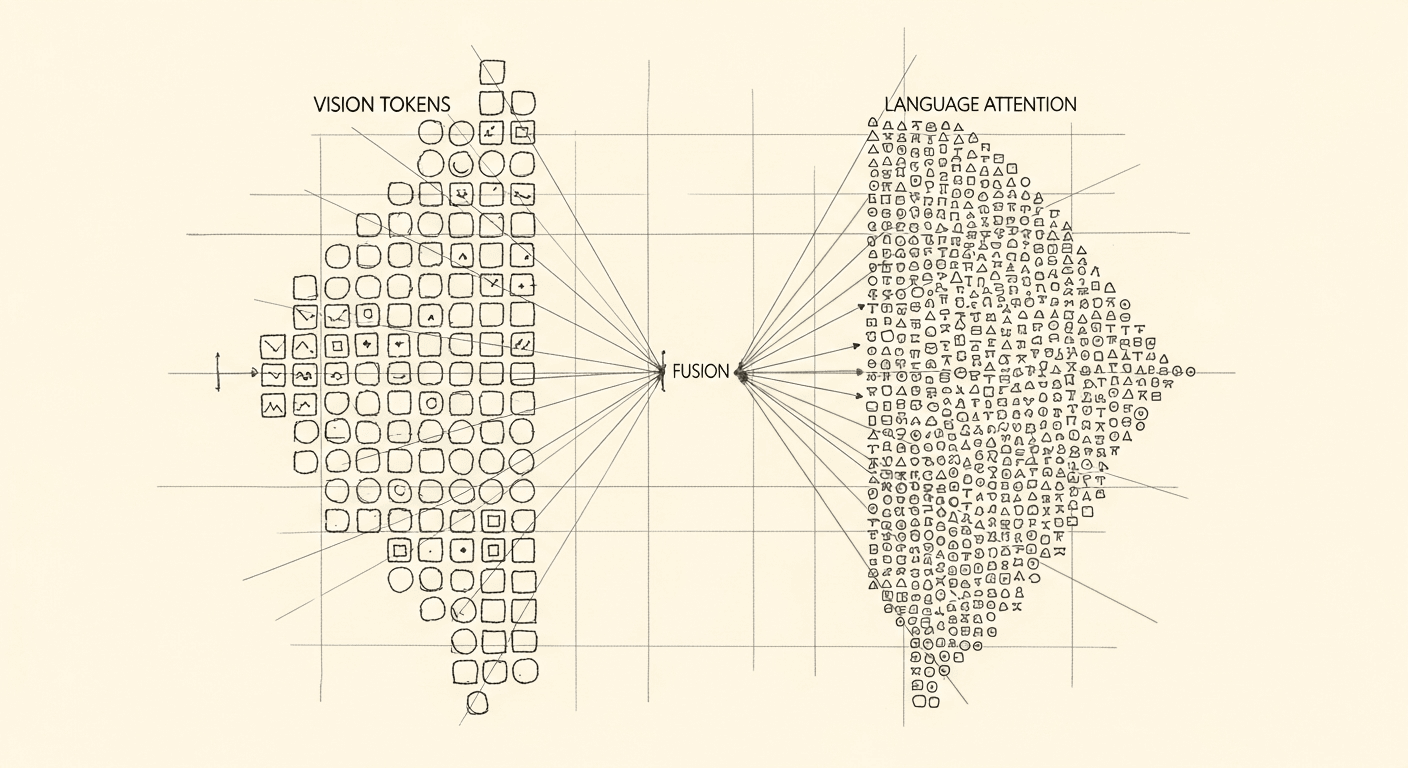
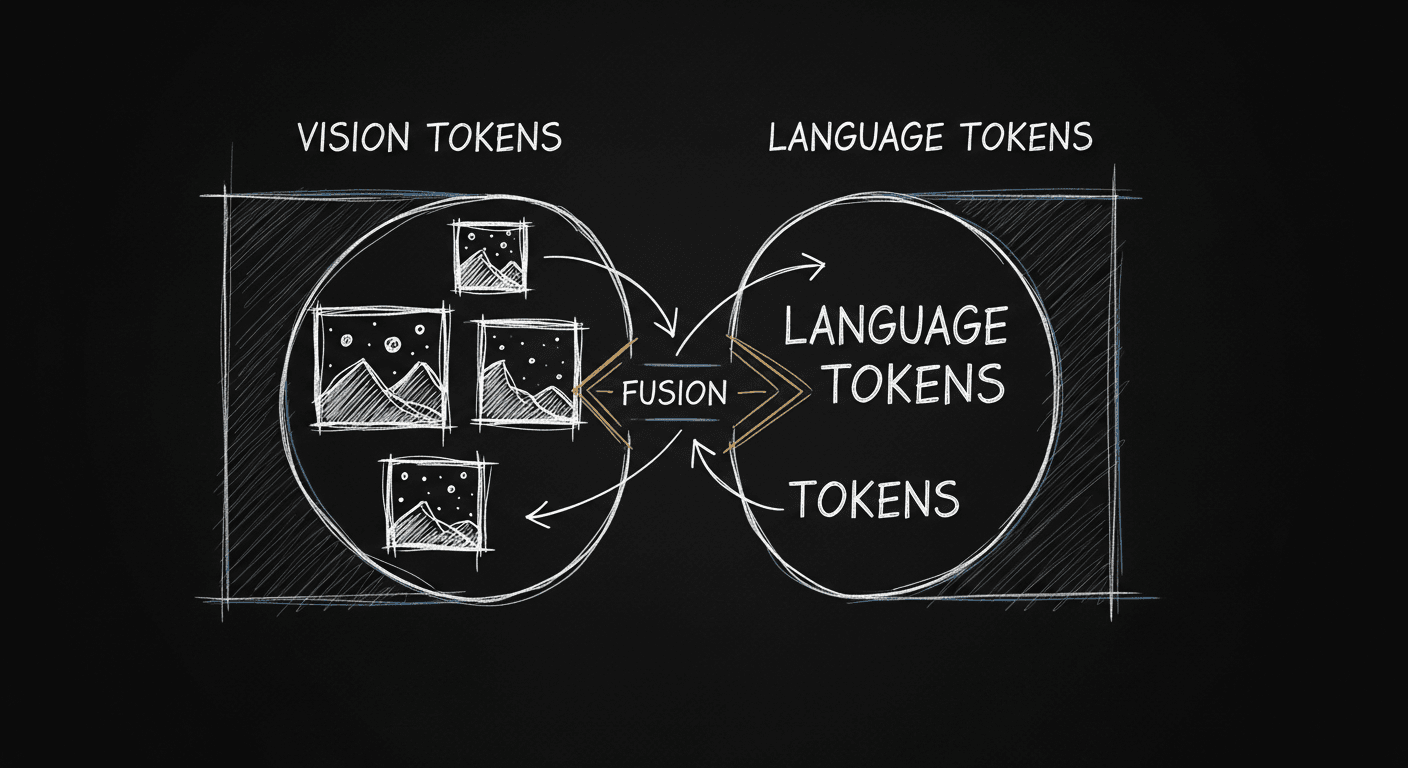
Vision + Language: How Multimodal LLMs Actually Work (And When to Use Them)
Multimodal LLMs integrate vision through two fundamentally different architectures. Knowing which one you need, and why, shapes every other technical choice in your build.
The Self-Healing Stack: What AI-Native Infrastructure Actually Means
The AI Cloud vision, where infrastructure monitors, optimizes, and repairs itself, is compelling. Some of it exists today. Most doesn't yet. What self-healing infrastructure looks like in practice, and what engineers should be doing to prepare.
FHIR Meets Graph Databases: Exploring Healthcare's Natural Network Structure
FHIR data is a graph. Treating it as flat tables is why most healthcare AI struggles with relationships between patients, providers, and encounters. What happens when you model it the way it actually is.


The Tools I Dropped When AI Changed My Development Workflow
AI coding assistants forced a full rethink of every layer of the dev stack. What I dropped, what I added, and the principle behind the restructuring.
From GPT-2 to DeepSeek: The Architectural Changes That Actually Mattered
I've been reading ML papers for 10 years. Most don't matter. These architectural choices did. RoPE, GQA, SwiGLU: each one solved a real scaling problem. What to look for when a new model claims 'better architecture.'

Building a GenAI Platform That Doesn't Collapse Under Its Own Weight
GenAI platforms don't fail because the models are bad. They fail because teams build everything at once. A practitioner's guide to layered architecture, from the minimal production-ready core to healthcare-grade guardrails.

Every Failed AI Product Has the Same Root Cause
The same failure pattern shows up everywhere: teams shipping fast and iterating on vibes instead of building systematic evaluation. Evals aren't a nice-to-have. They're the core competency of any serious AI product team.


The 6 Ways I've Watched GenAI Projects Fail (And How to Avoid Them)
GenAI projects in healthcare go sideways in predictable ways, sometimes with real patient consequences. Six failure modes that come up over and over again, and what to do instead.


When to Look Beyond Standard LLMs (And When to Stop Overthinking It)
Most teams should use a frontier API and move on. There are specific situations where alternative architectures matter: extreme latency, long-context scale, cost walls, privacy constraints. The decision framework.


When Recommendations Meet Language: The LLM-RecSys Convergence
Most AI stacks treat the recommendation engine and the language model as two separate systems that hand off to each other. A new class of hybrid models eliminates that seam. The implications for domain-specific AI are significant.
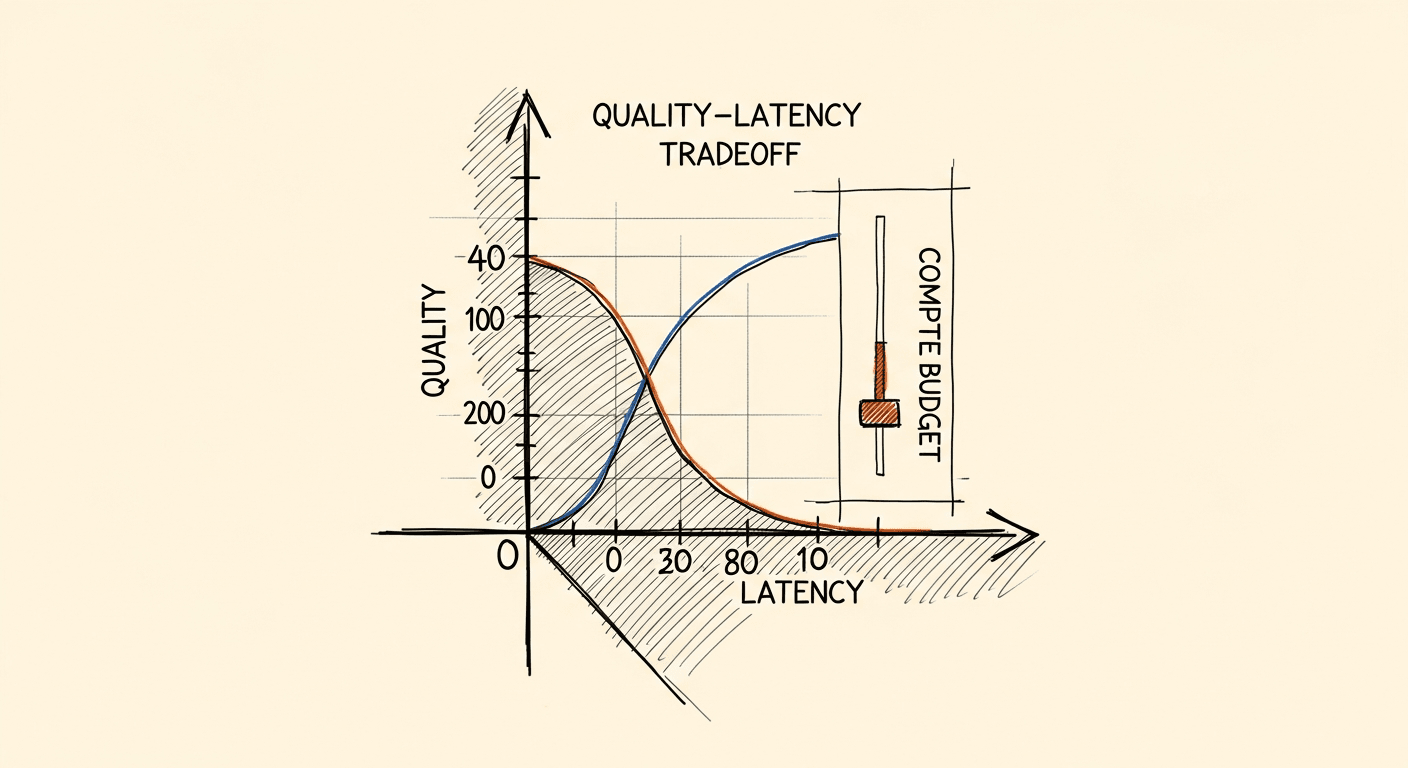

Trading Speed for Quality: A Practical Guide to Inference-Time Scaling
Inference-time scaling lets you tune the latency-quality tradeoff at runtime instead of at training time. When to use Best-of-N sampling, beam search, iterative refinement, or one-shot generation, with real examples from clinical AI.

Inside the Black Box: What Mechanistic Interpretability Means for Builders
Healthcare AI requires explainability. 'The model said so' is not a clinical rationale. Mechanistic interpretability is the research field trying to change that. What it offers practitioners today, where the gap is, and what to do in the meantime.
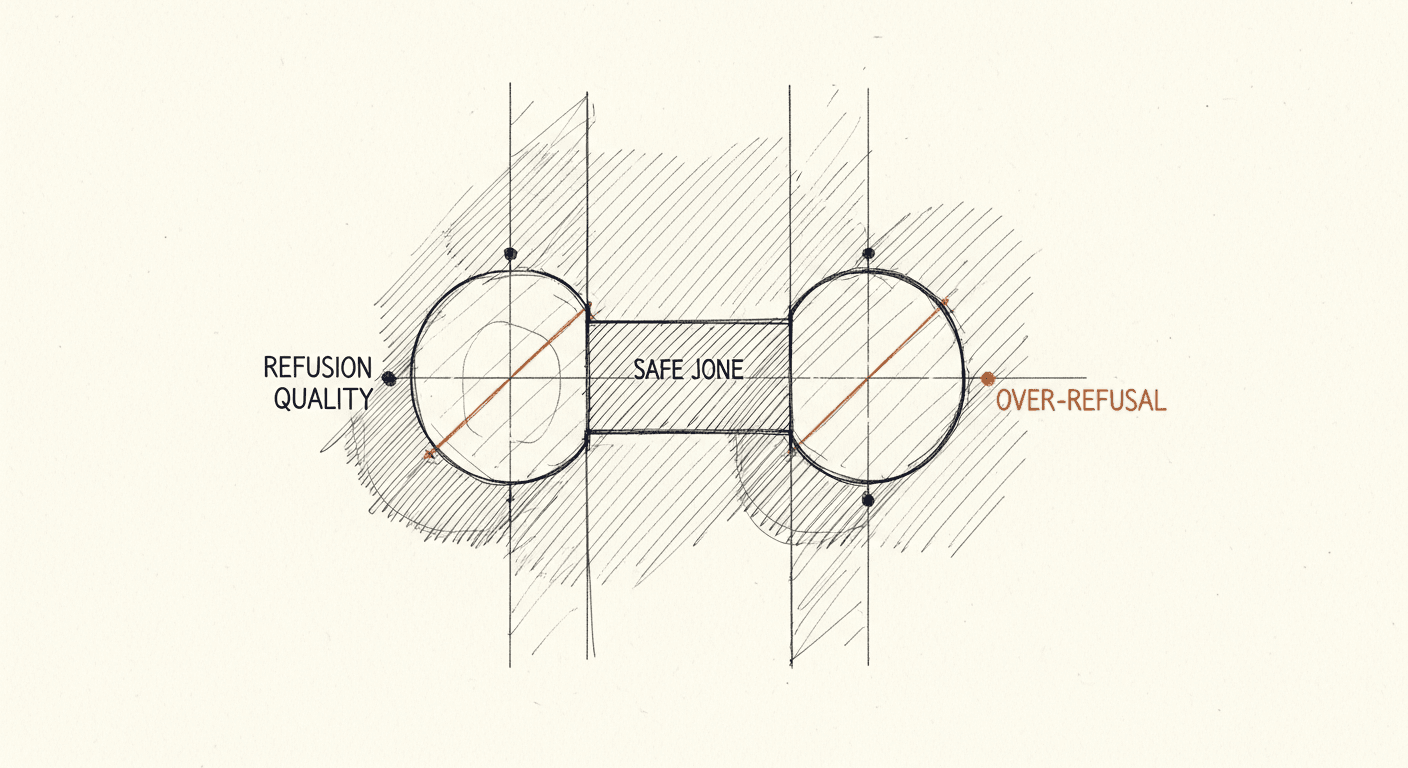

How to Actually Test If Your AI Will Say Something Dangerous
Most teams treat jailbreak testing as a vibe check. StrongREJECT achieves 0.90 Spearman correlation with human judgment. Automated safety evaluation is real, and there's no excuse not to build it into your pipeline.
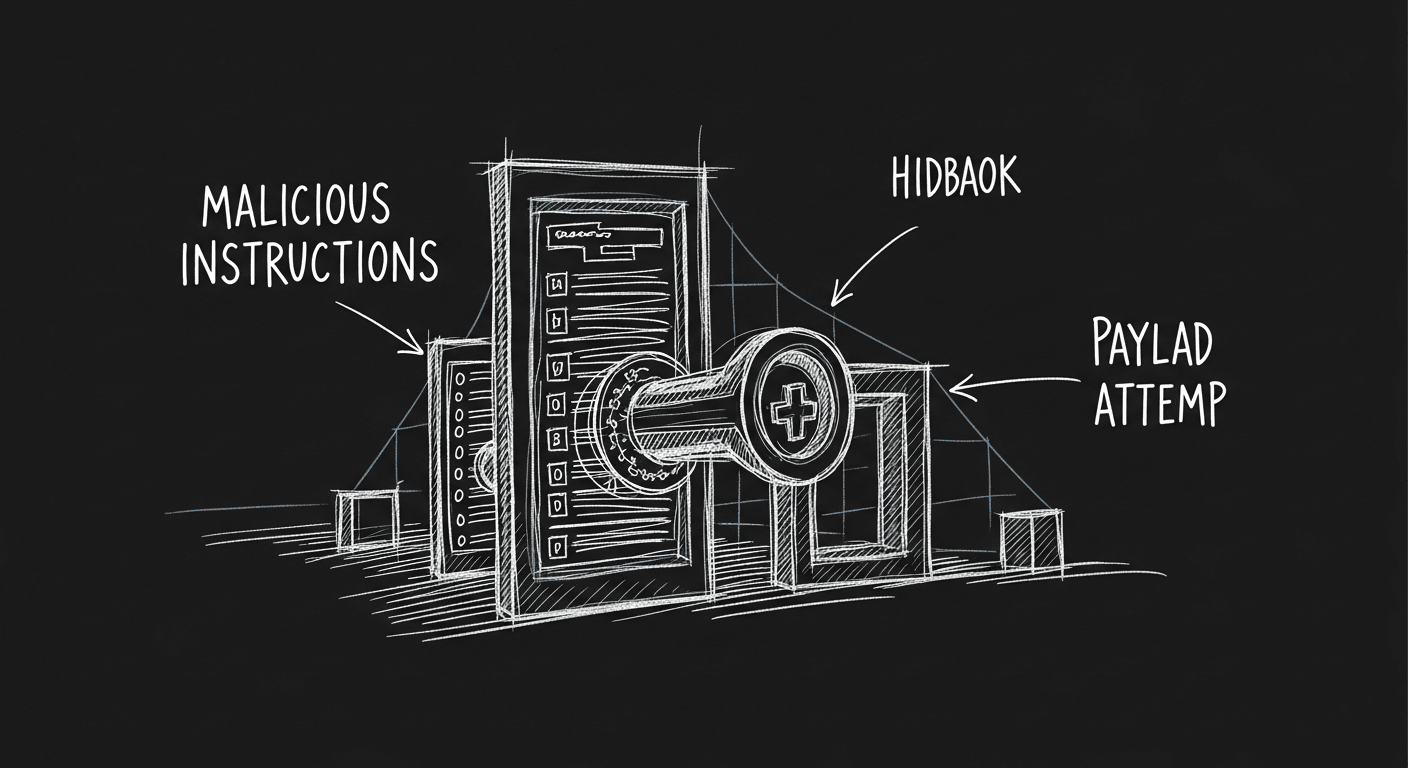
The Attack Your LLM App Is Definitely Vulnerable To
Prompt injection is the #1 OWASP threat to LLM applications and most teams aren't taking it seriously. What the attack looks like, why it's hard to stop, and how to harden your system.


The Honest Guide to LLM Evals: What Actually Works
Most teams skip real evals and wonder why their AI products degrade in production. The framework that holds up: from 30-minute manual reviews to binary scoring to knowing when your eval suite is finally doing its job.


Why Your LLM Evaluator Is Lying to You
LLM-as-judge evaluators feel like quality assurance but behave like rubber stamps. They fail hardest on the outputs that matter most: edge cases, safety-critical errors, domain-specific nuance. What to do instead.
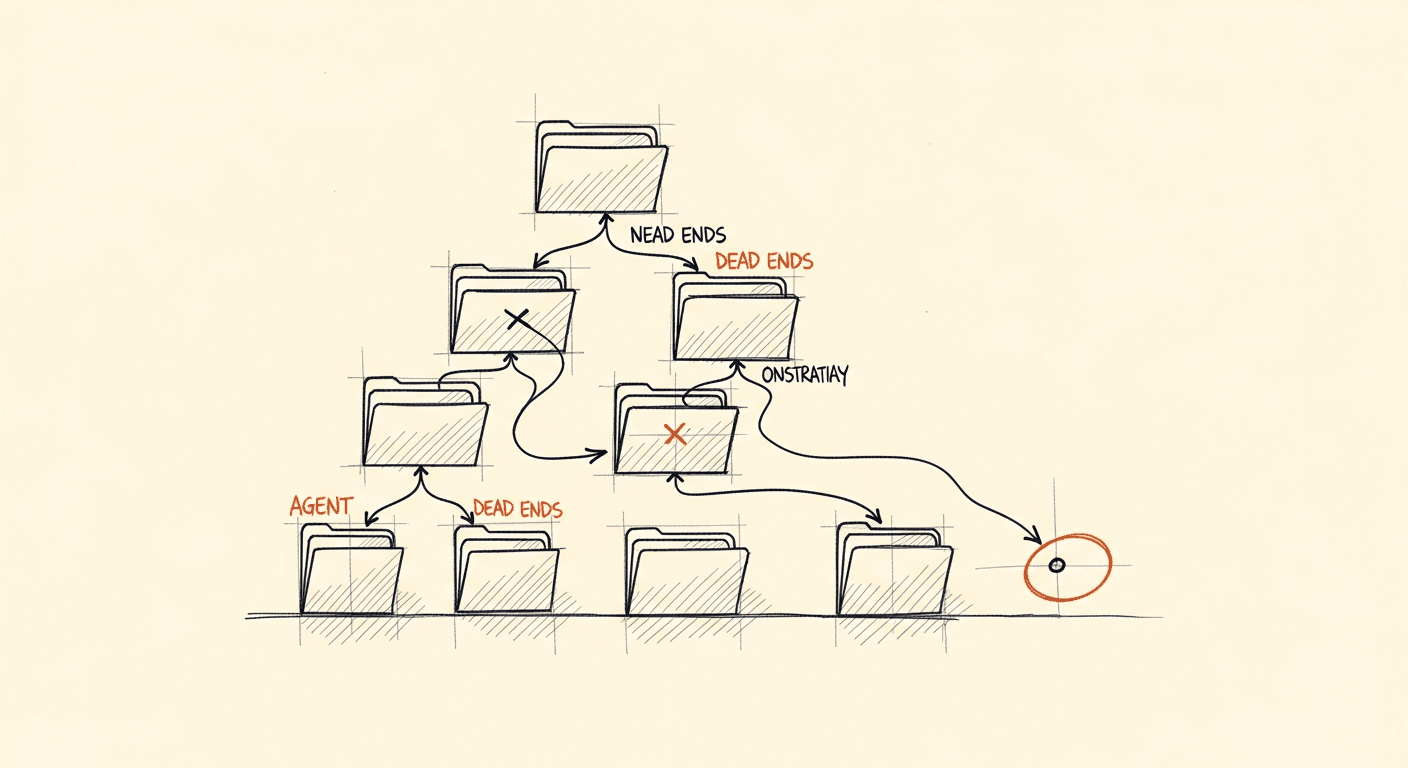
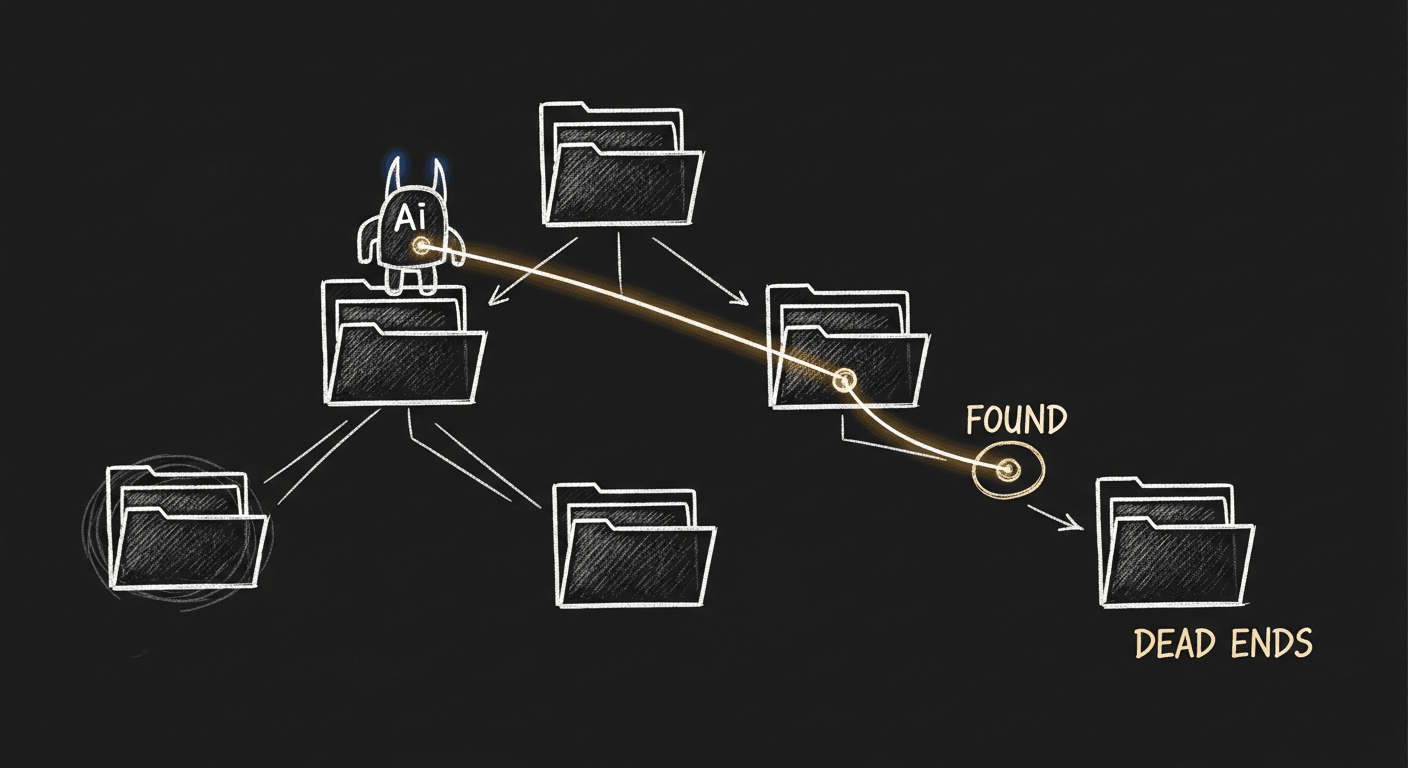
Why I Stopped Using RAG for Coding Agents (And What I Do Instead)
The instinct when building a coding agent is 'I need RAG to handle large codebases.' The better instinct is giving the agent tools to explore code the way a senior engineer would: reading files, following imports, tracing execution.

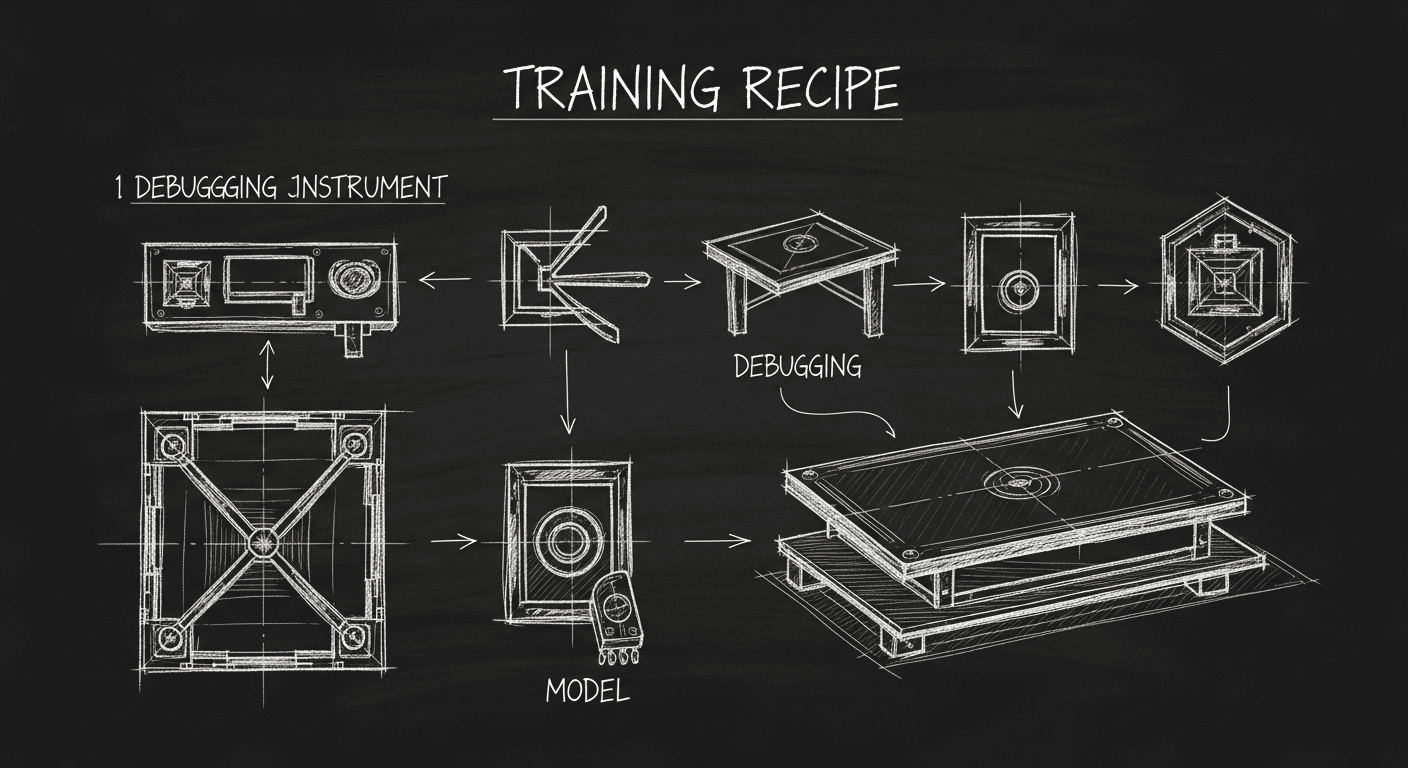
The Neural Net Training Recipe That Actually Works
I spent months chasing architecture fixes when my real problem was bad debugging hygiene. The training recipe that works: start simple, visualize everything, tune last. The unglamorous discipline that separates working models from expensive experiments.
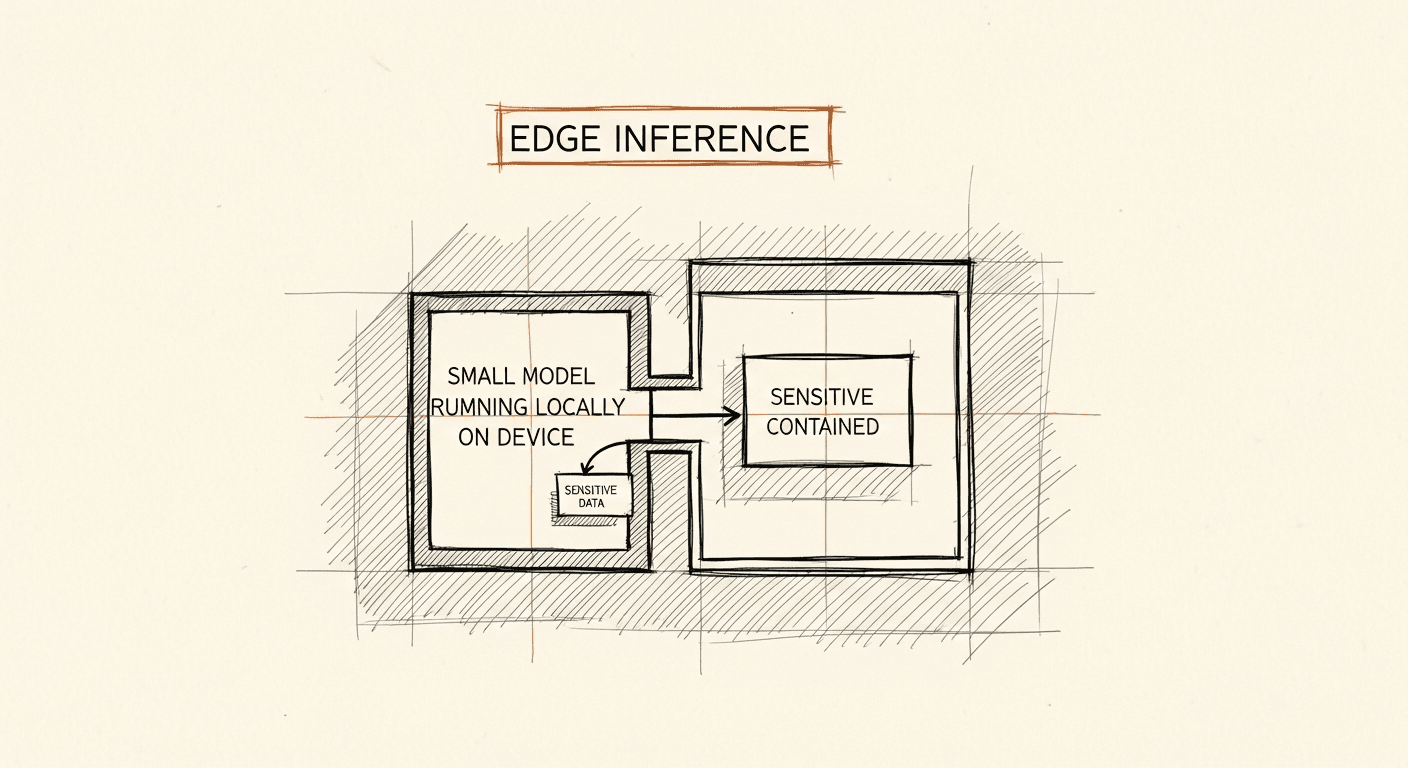

You Don't Need GPT-4 for That: Small Models and Edge Agents
Frontier models aren't required for agentic function calling. For healthcare AI, assuming they are can also be a compliance liability. When a fine-tuned 7B model is the right architecture, and when it isn't.
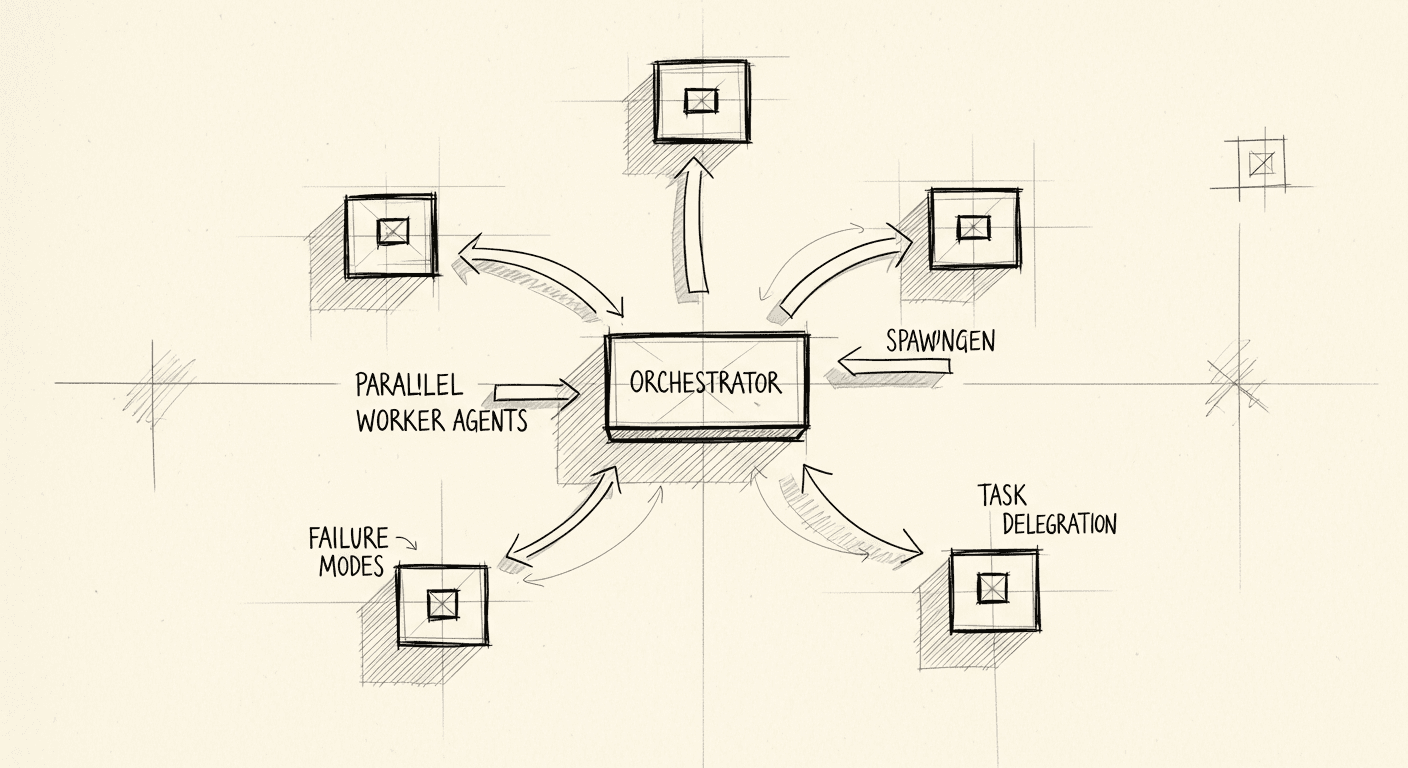
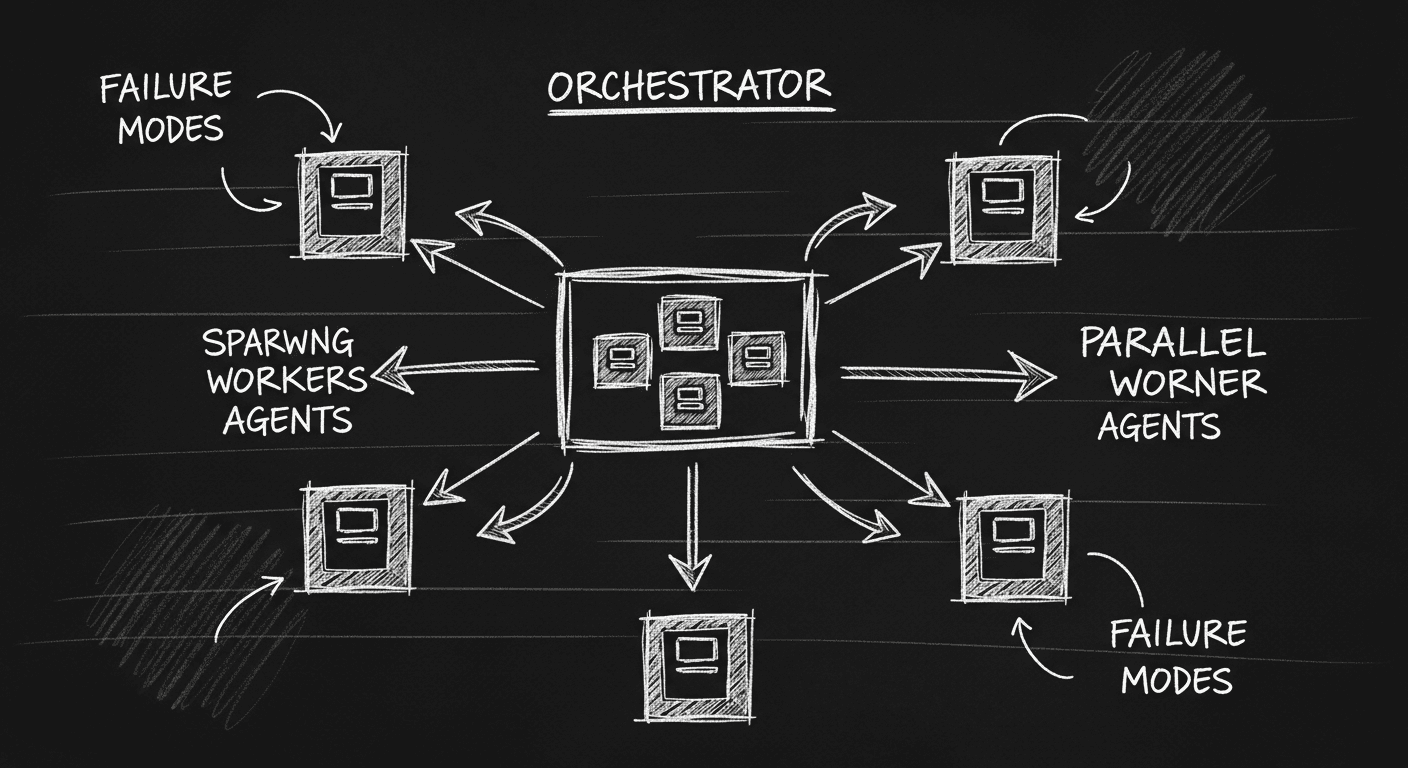
Multi-Agent Orchestration in Practice: What I Learned Building Parallel Agent Systems
The orchestrator/worker pattern is the key mental model for multi-agent systems. How to structure orchestrators, spawn and manage workers, aggregate results, and avoid the coordination failures that sink most implementations.
What It Actually Takes to Build a Real LLM Agent
Everyone's talking about agents. Few have shipped one that works in production. The failure modes, memory tradeoffs, and tool design decisions the architecture papers skip.
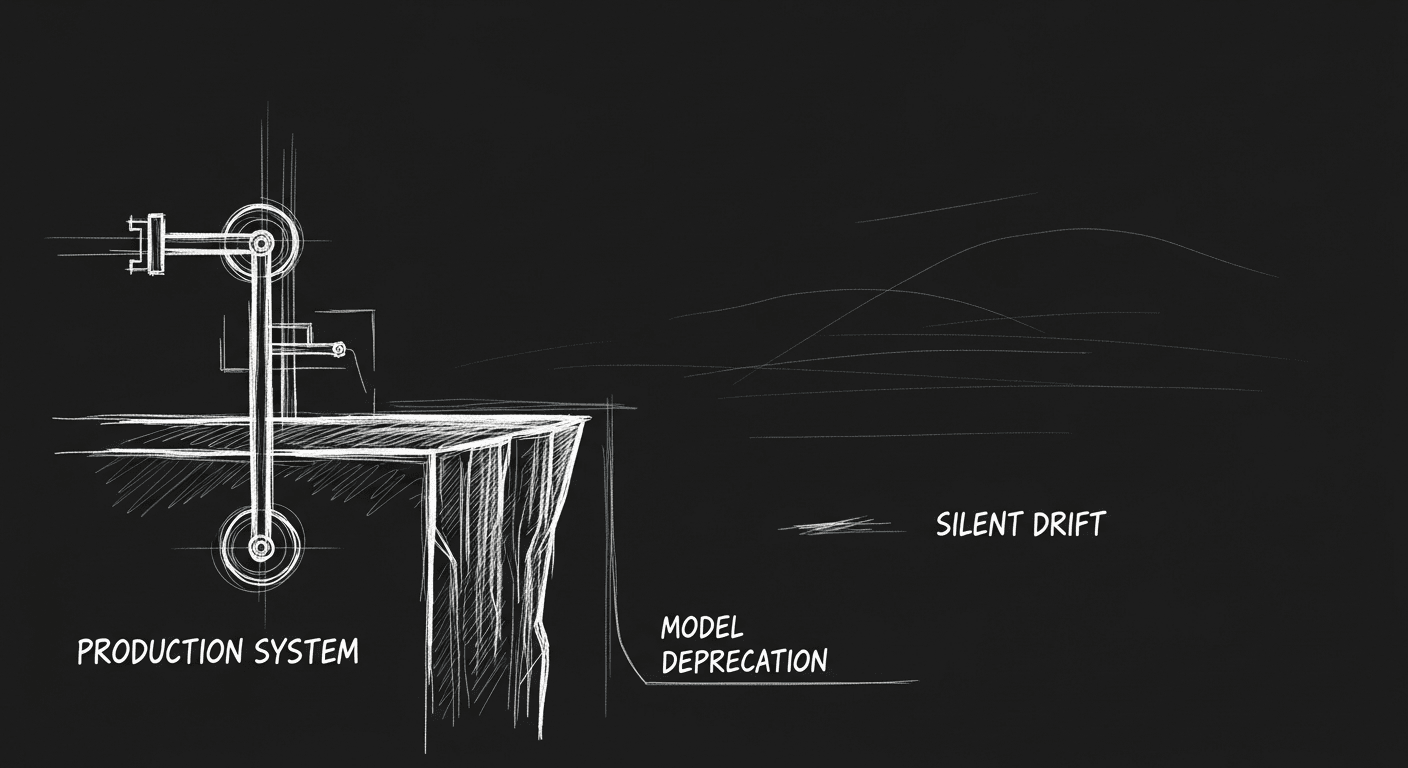
Three Hard Truths About LLMs in Production Nobody Warned Me About
Twelve years in ML and I still got burned. Stochasticity is a systems design problem. Your target model will be deprecated. Silent failures are worse than loud ones. What production healthcare AI taught me.
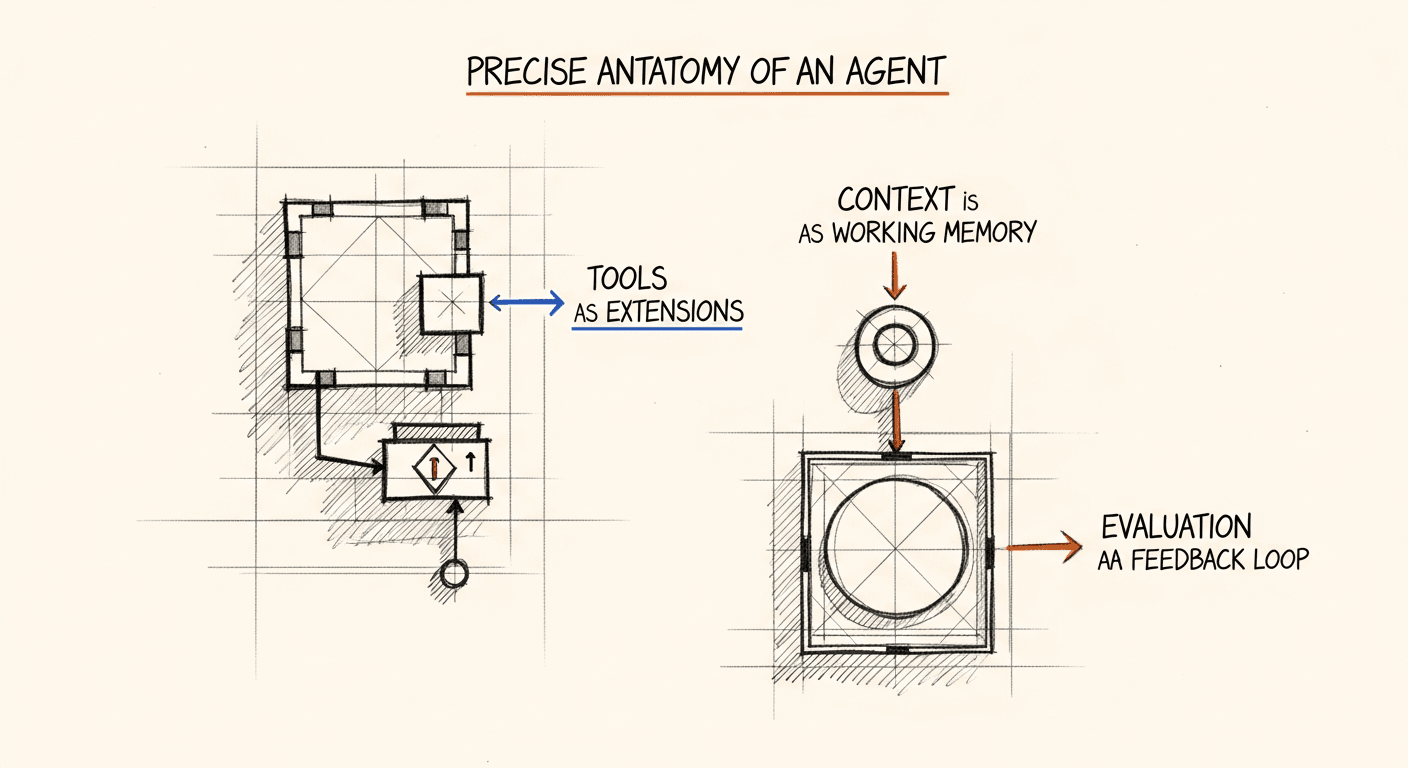
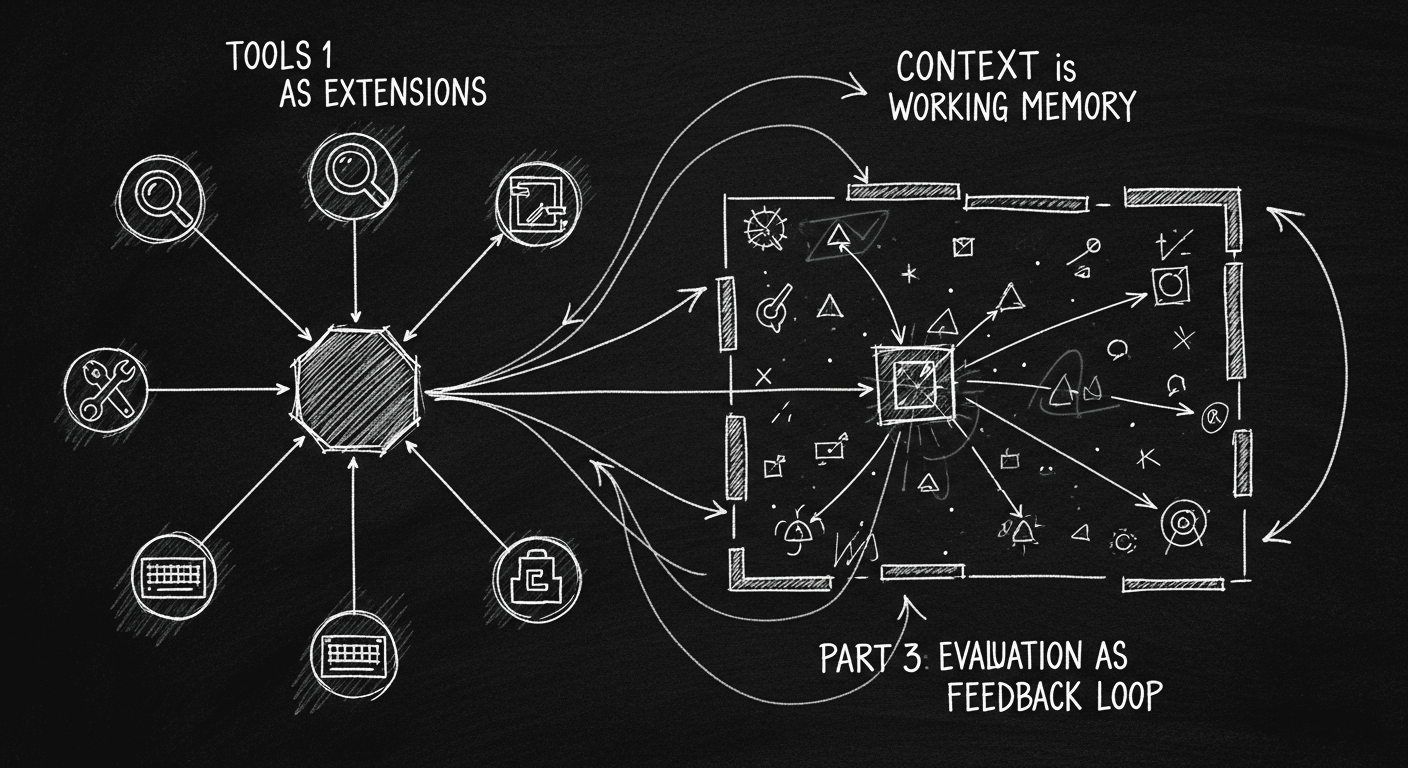
What AI Agents Actually Are (And What They Can't Do Yet)
Everyone's building 'agents.' Most are just APIs with a system prompt. The precise definition, the components that matter, the failure modes I've hit, and how to pick the right pattern for your problem.
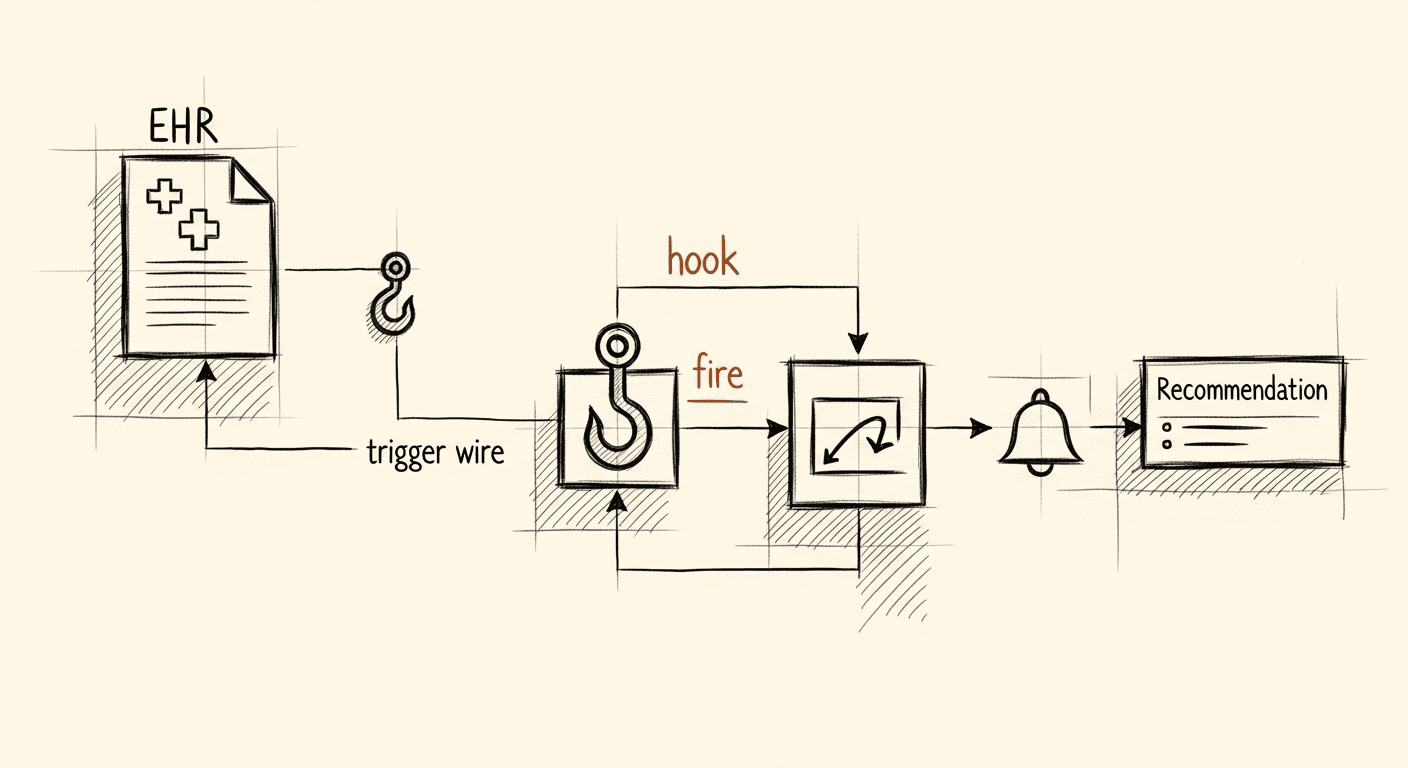
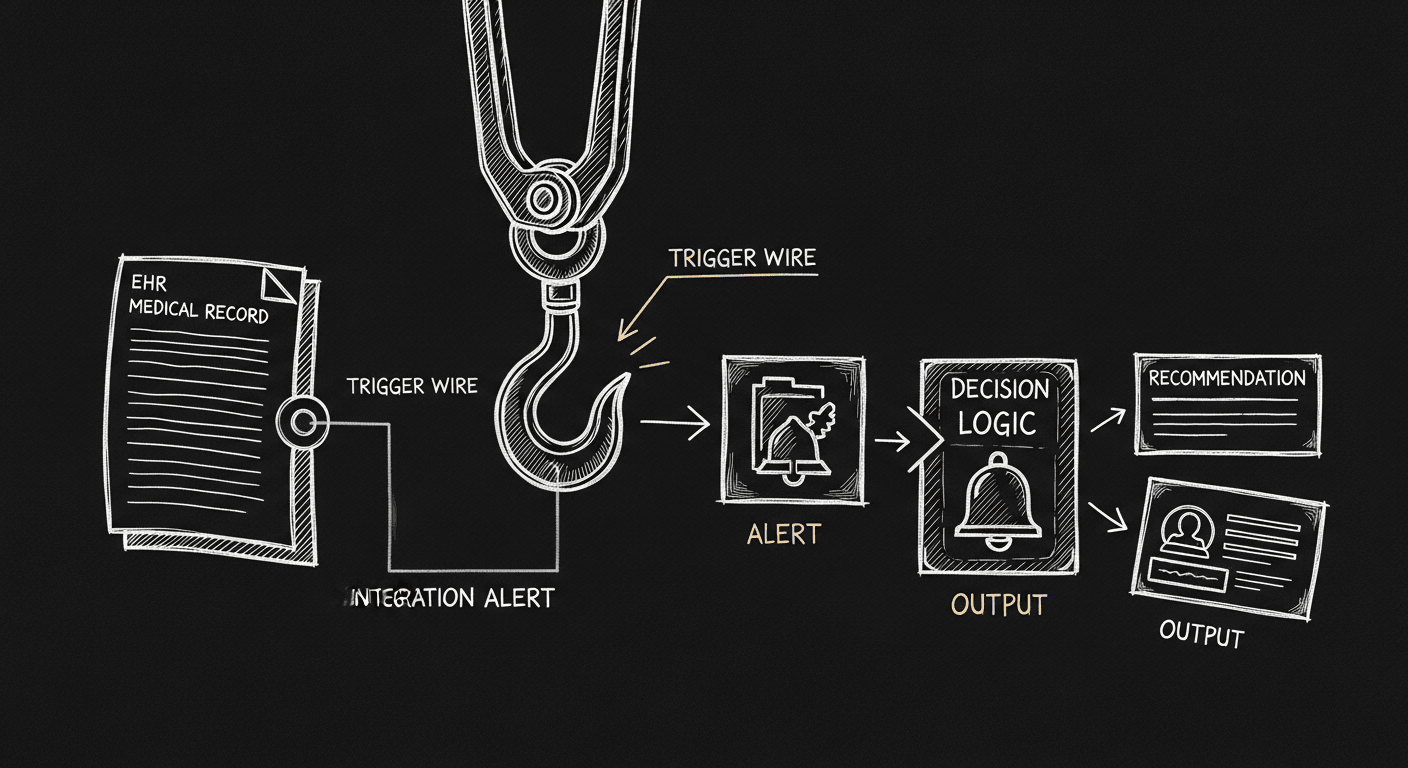
CDS Hooks: What Nobody Tells You Before You Build
CDS Hooks look straightforward until you try to get them working in Epic. Six months of integration reality the documentation glosses over.
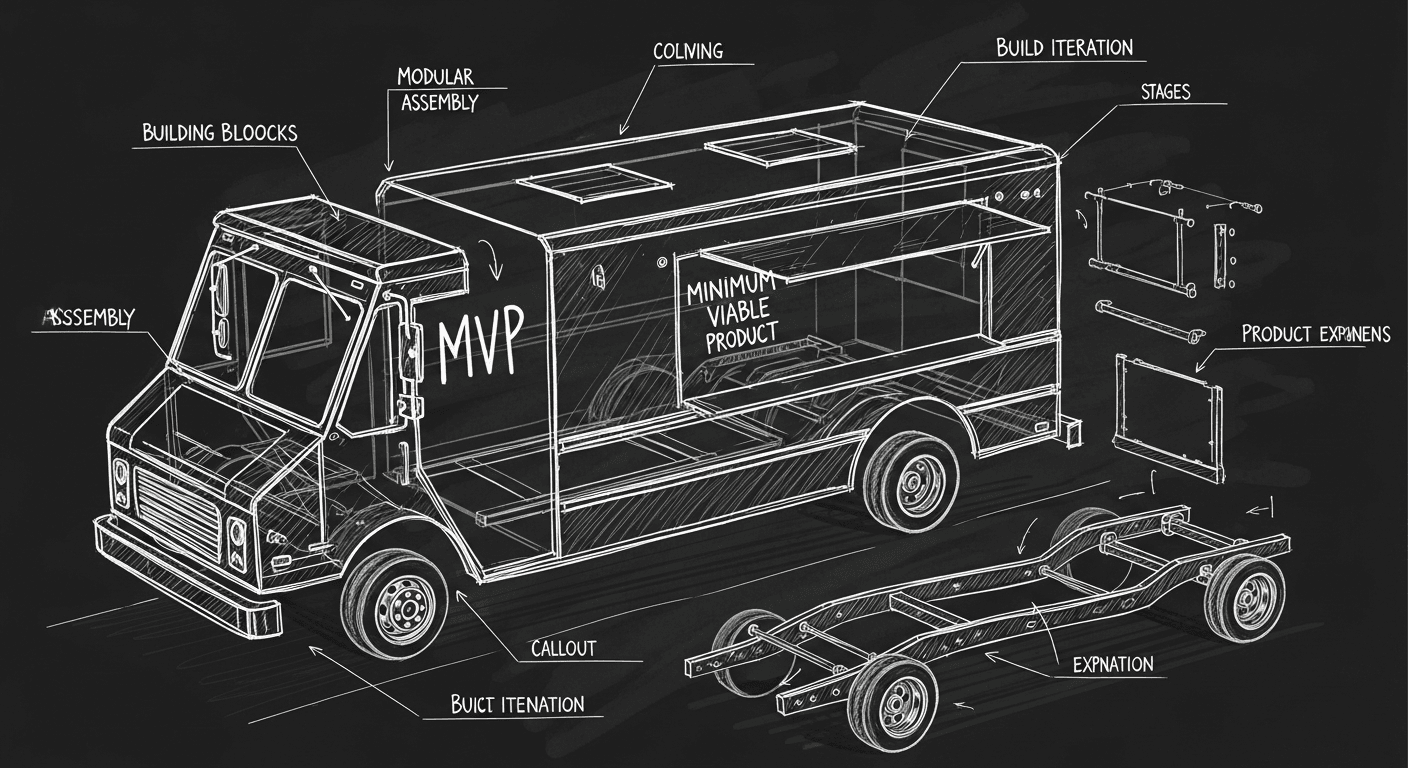
The Food Truck Method: Building MVPs That Don't Suck
Most MVPs turn into dumpster fires not because teams move too fast, but because they move fast in the wrong direction. The food truck method for building without the regret.


HIPAA Consent: What Engineers Actually Need to Know
HIPAA documentation runs to thousands of pages. What engineers building healthcare apps need to know, and what's compliance theater.